
不靠死记布局也能按图生成,多实例生成的布局控制终于“可控且不串脸”了丨浙大团队
不靠死记布局也能按图生成,多实例生成的布局控制终于“可控且不串脸”了丨浙大团队尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现:
来自主题: AI技术研报
10700 点击 2025-12-22 09:33
 搜索
搜索
尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现:
AI PC能干的事儿,终究是超出了我的认知。
今天聊一聊我们如何做高质量rerank。

随着通用型(Generalist)机器人策略的发展,机器人能够通过自然语言指令在多种环境中完成各类任务,但这也带来了显著的挑战。

在大型语言模型(LLM)的应用落地中,RAG(检索增强生成)是解决模型幻觉和知识时效性的关键技术。
最近,视频会议软件公司 Zoom 发布了一条出人意料的消息:他们宣称在“人类最后的考试”(Humanity s Last Exam,简称 HLE)这个号称当前 AI 领域最具挑战性的基准测试上,取得了 48.1% 的成绩,比此前由 Google Gemini 3 Pro(带工具)保持的 45.8% 高出 2.3 个百分点。
想象一下,只需要一句话描述,AI 就能为你拍出一部完整的短剧?为了让这个想法变成现实,香港大学黄超教授团队开源了 ViMax 框架,并在 GitHub 获得 1.4k + 星标,专注于 Agentic Video Generation 的前沿探索。通过多智能体协作,ViMax 实现了真正的 "自编自导自演"—— 从创意构思到成片输出的完整自动化,把传统影视制作的每个环节都搬进了 AI 世界。

主攻 AI 视频与多媒体生成技术的独角兽 Runway 也来了一波大的:一口气来了 5 个「激动人心的宣布」。这一波更新之猛,甚至让人觉得他们是不是把过去半年的大招一次性全放了出来。Runway 这一波发布,不仅刷新了视频生成的各项指标,更重要的是,他们正式对外展示了其在通用世界模型(General World Models/GWM)上的野心。
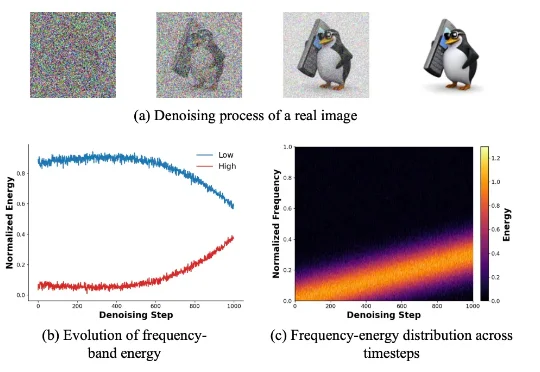
新加坡国立大学 LV Lab(颜水成团队) 联合电子科技大学、浙江大学等机构提出 FeRA (Frequency-Energy Constrained Routing) 框架:首次从频域能量的第一性原理出发,揭示了扩散去噪过程具有显著的「低频到高频」演变规律,并据此设计了动态路由机制。

今日凌晨,比OpenAI早一个小时,谷歌甩出了3个Agent大招:Deep Research Agent功能更新,并首次向开发者开放;开源新网络研究Agent基准DeepSearchQA,旨在测试Agent在网络研究任务中的全面性;推出新交互API(Interactions API)。