
一家AI找矿公司拿到4400万B轮融资
一家AI找矿公司拿到4400万B轮融资瑞士投资机构Blue Earth Capital 牵头,必和必拓Ventures 及力拓集团参与投资。比尔・盖茨旗下的Ventures(BEV)也参与了此次融资。 总部位于卡尔加里的矿业科技初创公司GeologicAI已完成4400万美元的B轮融资。
来自主题: AI资讯
8571 点击 2025-07-24 15:43
 搜索
搜索
瑞士投资机构Blue Earth Capital 牵头,必和必拓Ventures 及力拓集团参与投资。比尔・盖茨旗下的Ventures(BEV)也参与了此次融资。 总部位于卡尔加里的矿业科技初创公司GeologicAI已完成4400万美元的B轮融资。
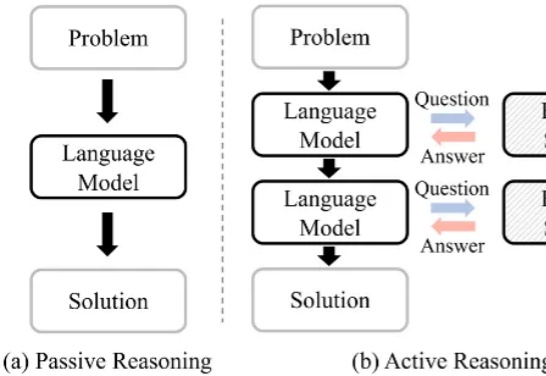
大语言模型(Large Language Model, LLM)在复杂推理任务中表现卓越。借助链式思维(Chain-of-Thought, CoT),LLM 能够将复杂问题分解为简单步骤,充分探索解题思路并得出正确答案。LLM 已在多个基准上展现出优异的推理能力,尤其是数学推理和代码生成。

在正式走近ChatGPT Agent之前,让我们介绍一下这次谈话的几位主角,他们分别是OpenAI团队核心成员Isa Fulford、Casey Chu和孙之清。我们团队分别开发了Operator和Deep Research,在分析用户请求时发现,Deep Research的用户非常希望模型能够访问需要付费订阅的内容或有门槛的资源,而Operator恰好具备这种能力。

这一行 30 多人,他们来是接到了某大厂的举报,来对我们 Get 笔记进行深入调查,举报的理由是“涉嫌不正当竞争”,举报的根源是我们在 Get笔记里,给用户提供了对视频号直播和视频号短视频,可以变成图文笔记的功能,节约用户时间。

Vibe Coding 2.0来临,中文就是最热门编程语言!全新ShellAgent横空出世,无需敲代码,几句话即可搞定一个APP。人手一个爆款Agent时代,即将到来。
ChatGPT刚刚给火热的Agent市场添把柴,这边AI搜索市场却要变天。Bing Search API将于8月11日关停,所有Bing Search API都将完全停用,同时不再接受新用户注册。

自 ChatGPT 引爆公众认知以来,AI 开始渗透进写作、编程、设计等多个应用场景,推动人类进入“智能体(Agent)”时代。曾经遥不可及的自动化交互,如今正在成为现实。在这背后,一场关于基础设施的重构也悄然展开——从模型能力到部署体验,谁能打通智能 Agent 的“最后一公里”,谁就掌握了这场范式变革的主动权。
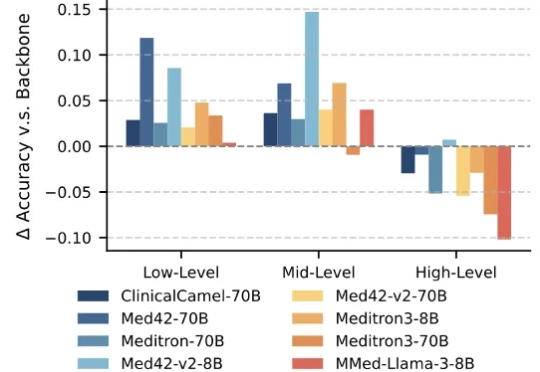
大语言模型(Large Language Models,LLMs)技术的迅猛发展,正在深刻重塑医疗行业。医疗领域正成为这一前沿技术的 “新战场” 之一。大模型具备强大的文本理解与生成能力,能够快速读取医学文献、解读病历记录,甚至基于患者表述生成初步诊断建议,有效辅助医生提升诊断的准确性与效率。

扎心了!谷歌这边刚刚宣布获得IMO金牌,三位核心团队成员就被曝离开加入Meta。

请你让我享受发现美、创造美的过程。