
直接从像素到单词:这个原生大模型统一单图、多图、视频和空间智能
直接从像素到单词:这个原生大模型统一单图、多图、视频和空间智能今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。
来自主题: AI技术研报
7515 点击 2026-06-24 16:06
 搜索
搜索
今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。
在InternVL-2.5上实现10倍吞吐量提升,模型性能几乎无损失。

在实际应用过程中,闭源模型(GPT-4o)等在回复的全面性、完备性、美观性等方面展示出了不俗的表现。
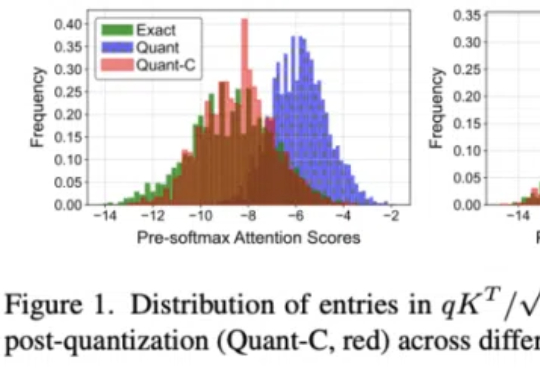
尽管近期 Qwen2-VL 和 InternVL-2.0 的出现将开源多模态大模型的 SOTA 提升到了新高度,但巨大的计算开销限制了其在很多场景下的应用。
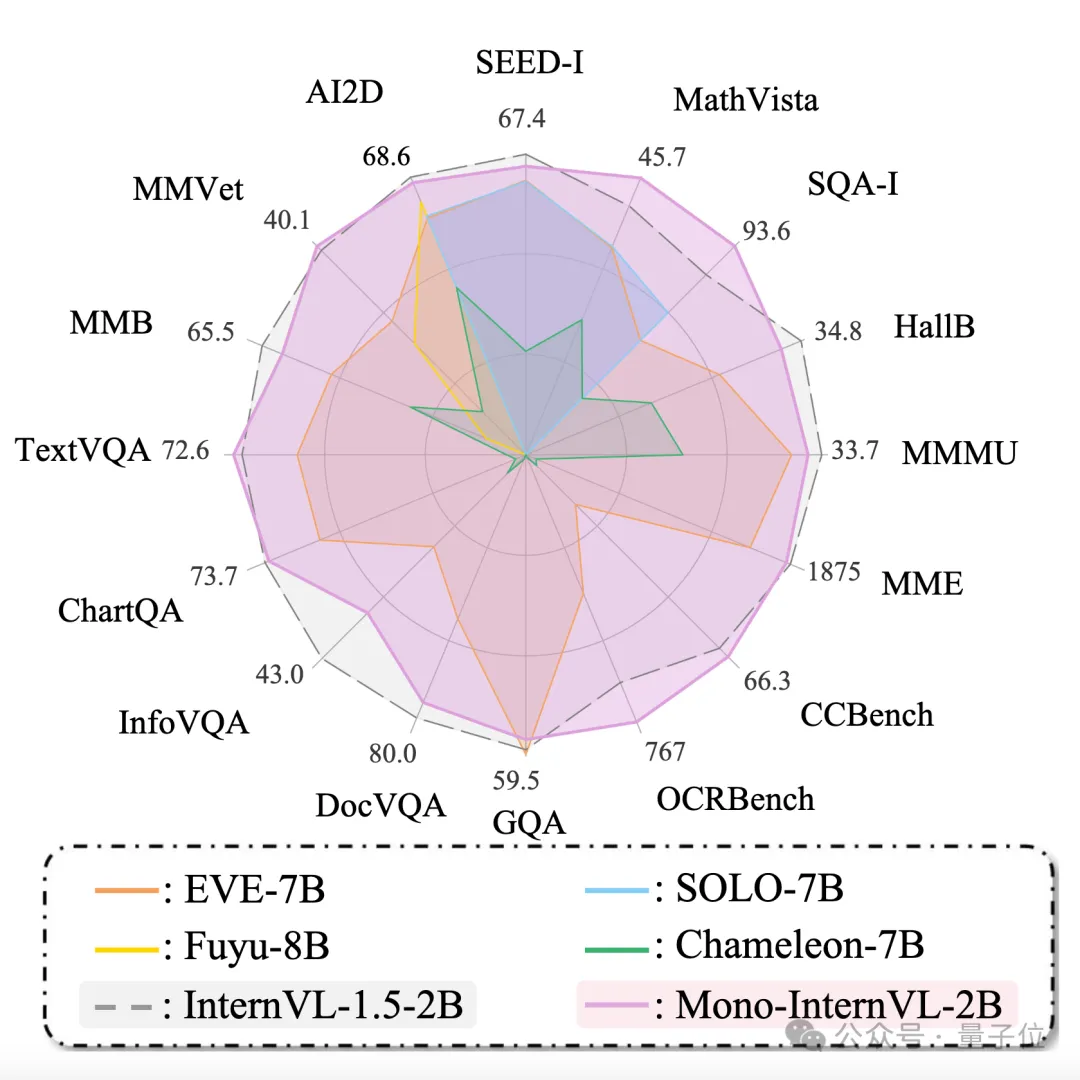
原生多模态大模型性能瓶颈,迎来新突破! 上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。 与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。

随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现出了越来越接近闭源的性能。
CVPR正在进行中,中国科研力量再次成为场内外焦点之一。