
维基百科+大模型打败幻觉!斯坦福WikiChat性能碾压GPT-4,准确率高达97.3%
维基百科+大模型打败幻觉!斯坦福WikiChat性能碾压GPT-4,准确率高达97.3%大模型固有的幻觉问题严重影响了LLM的表现。斯坦福最新研究利用维基百科数据训练大模型,得到的WikiChat成为首个几乎不产生幻觉的聊天机器人。
来自主题: AI资讯
6305 点击 2024-01-03 14:00
 搜索
搜索
大模型固有的幻觉问题严重影响了LLM的表现。斯坦福最新研究利用维基百科数据训练大模型,得到的WikiChat成为首个几乎不产生幻觉的聊天机器人。

近日,美团、浙大等推出了能够在移动端部署的多模态大模型,包含了 LLM 基座训练、SFT、VLM 全流程。也许不久的将来,每个人都能方便、快捷、低成本的拥有属于自己的大模型。

作者重点关注了基于 Transformer 的 LLM 模型体系结构在从预训练到推理的所有阶段中优化长上下文能力的进展。
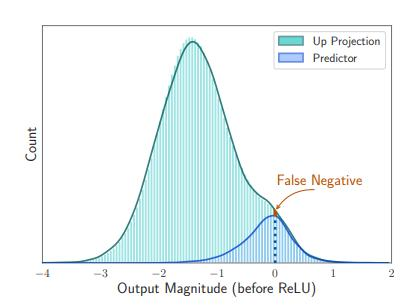
大模型领域最新的一个热门趋势是把模型塞到手机里。而最应该做这个研究的公司终于带着它的论文现身,那就是苹果。

大型语言模型(LLM)虽然在诸多下游任务上展现出卓越的能力,但其实际应用还存在一些问题。其中,LLM 的「幻觉(hallucination)」问题是一个重要缺陷。

经过23年的生成式AI之年,24年AI会有哪些新突破?大佬预测,即使GPT-5发布,LLM在本质上仍然有限,在24年,基本的AGI也不足以实现。

2023年的LLM开源社区都发生了什么?来自Hugging Face的研究员带你回顾并重新认识开源LLM

近日,来自华为诺亚方舟实验室、北京大学等机构的研究者提出了盘古 π 的网络架构,尝试来构建更高效的大模型架构。
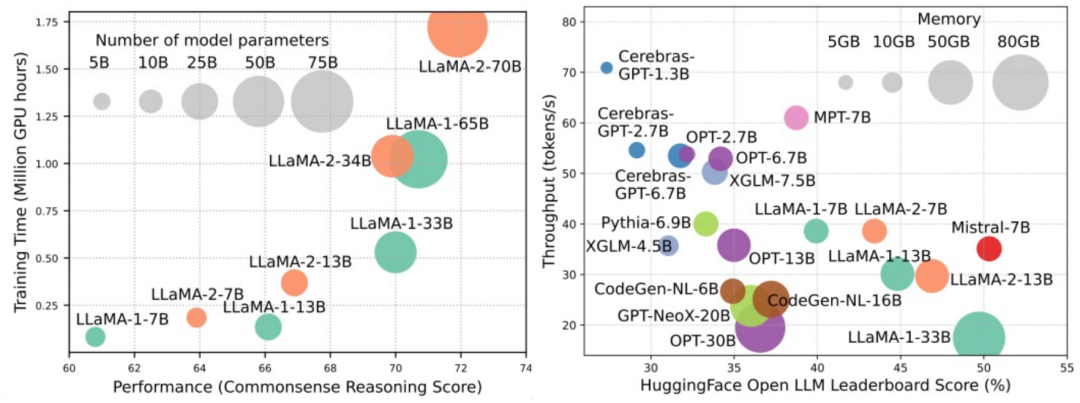
大规模语言模型(LLMs)在很多关键任务中展现出显著的能力,比如自然语言理解、语言生成和复杂推理,并对社会产生深远的影响。然而,这些卓越的能力伴随着对庞大训练资源的需求(如下图左)和较长推理时延(如下图右)。因此,研究者们需要开发出有效的技术手段去解决其效率问题。

ChatGPT 凭一己之力掀起了 AI 领域的热潮,火爆全球,似乎开启了第四次工业革命。