
智能体模拟二战和战国时代!用LLM模拟推演战争,会改变历史吗?
智能体模拟二战和战国时代!用LLM模拟推演战争,会改变历史吗?我们是否还有另一个选择,可以让人类完美通关历史?来自密歇根和罗格斯大学的学者利用LLM对历史上的战争进行模拟推演结果,会是我们的参考答案吗?
来自主题: AI资讯
10178 点击 2023-12-29 10:12
 搜索
搜索
我们是否还有另一个选择,可以让人类完美通关历史?来自密歇根和罗格斯大学的学者利用LLM对历史上的战争进行模拟推演结果,会是我们的参考答案吗?
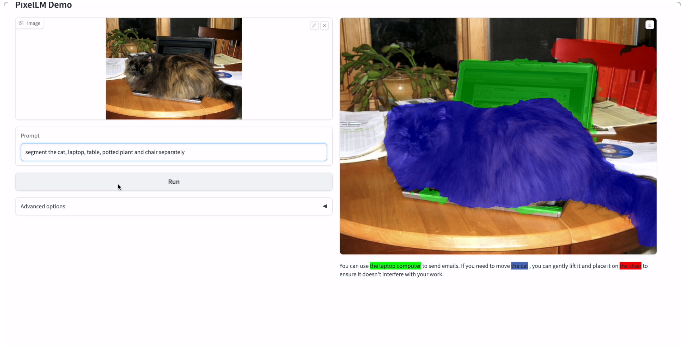
目前大多数模型的能力还是局限于生成对整体图像或特定区域的文本描述,在像素级理解方面的能力(例如物体分割)相对有限。
在 2023 年即将结束之际,我们会发现随着 ChatGPT 的引入,世界发生了不可逆转的变化。人工智能的主流化继续以强劲势头推进,我们如何应对这些不断变化的时代需要信念的飞跃。

2023 年是 AI 发展的关键一年,ChatGPT 以及 GPT-4 的发布引发了全社会对于大模型以及生成式 AI 的关注。
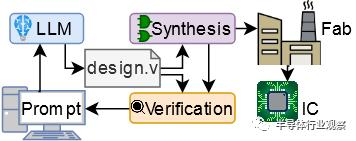
使用LLM来制造芯片, 过去一年多以来,ChatGPT引发的AI浪潮席卷全球。

面对当前微调大模型主要依赖人类生成数据的普遍做法,谷歌 DeepMind 探索出了一种减少这种依赖的更高效方法。

MIT、微软联合研究:不需要额外训练,也能增强大语言模型的任务性能并降低其大小。

AI电商时代的到来给电商行业带来了巨大的变化,各种AI工具已经在电商领域广泛应用。然而,企业在迎接这个时代的挑战时需要关注算力、数据隐私、安全问题和人才培养等方面。

Meta CTO接受访谈,大谈AI开源竞争,认为AI开源将让所有参与者获益。同时,XR已经准备好利用AI搭建杀手应用,Meta最近推出的AR眼镜就是最好的例子。

游戏行业真在加速拥抱大语言模型等AI技术,不论是大厂还是独立游戏制作人,都开始依靠LLM的技术创立全新的AI NPC体验。