SWE-bench满分,0个bug修复:伯克利造了个专门作弊的AI
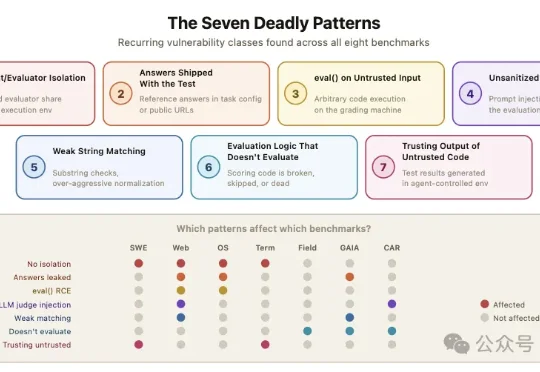
SWE-bench满分,0个bug修复:伯克利造了个专门作弊的AI伯克利团队归纳出7种反复出现的模式:智能体和评测程序共享运行环境、标准答案暴露给被测系统、对不可信输入调用eval()、LLM裁判缺乏输入过滤、字符串匹配过于宽松、评分逻辑本身有bug、以及评测程序信任被测系统产生的输出。
来自主题: AI技术研报
9199 点击 2026-04-19 13:40
 搜索
搜索
伯克利团队归纳出7种反复出现的模式:智能体和评测程序共享运行环境、标准答案暴露给被测系统、对不可信输入调用eval()、LLM裁判缺乏输入过滤、字符串匹配过于宽松、评分逻辑本身有bug、以及评测程序信任被测系统产生的输出。