Agent全自动搭建代码运行环境,实时更新解决评测过拟合/数据污染问题|微软
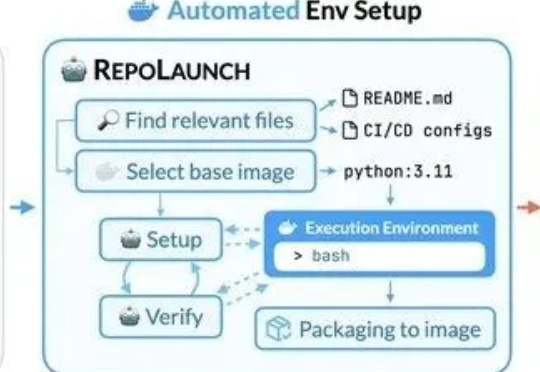
Agent全自动搭建代码运行环境,实时更新解决评测过拟合/数据污染问题|微软长期以来主流的代码修复评测基准SWE-bench面临数据过时、覆盖面窄、手动维护成本高等问题,严重制约了AI模型真实能力的展现。
来自主题: AI技术研报
9332 点击 2025-06-20 15:23
 搜索
搜索
长期以来主流的代码修复评测基准SWE-bench面临数据过时、覆盖面窄、手动维护成本高等问题,严重制约了AI模型真实能力的展现。