刚刚,Thinking Machines Lab博客提出在策略蒸馏,Qwen被cue 38次
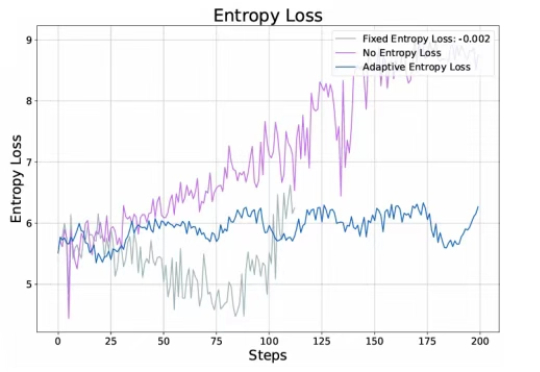
刚刚,Thinking Machines Lab博客提出在策略蒸馏,Qwen被cue 38次刚刚,不发论文、爱发博客的 Thinking Machines Lab (以下简称 TML)再次更新,发布了一篇题为《在策略蒸馏》的博客。在策略蒸馏(on-policy distillation)是一种将强化学习 (RL) 的纠错相关性与 SFT 的奖励密度相结合的训练方法。在将其用于数学推理和内部聊天助手时,TML 发现在策略蒸馏可以极低的成本超越其他方法。
来自主题: AI技术研报
9002 点击 2025-10-28 10:50