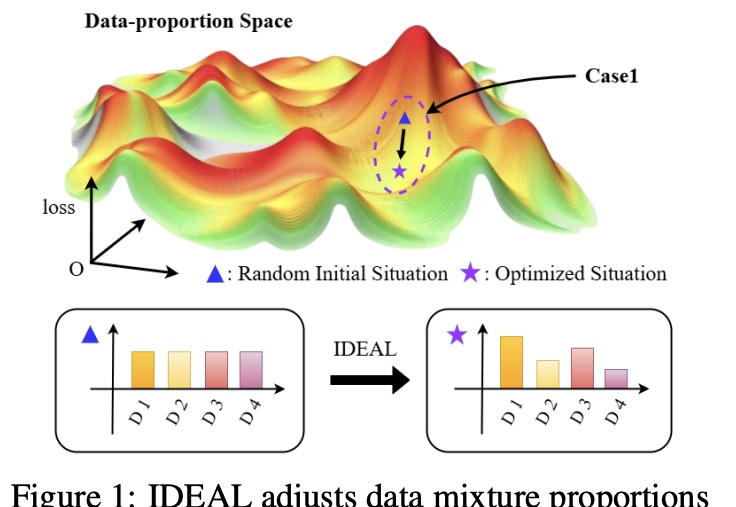
一招缓解LLM偏科!调整训练集组成,“秘方”在此 | 上交大&上海AI Lab等
一招缓解LLM偏科!调整训练集组成,“秘方”在此 | 上交大&上海AI Lab等大幅缓解LLM偏科,只需调整SFT训练集的组成。
来自主题: AI技术研报
8139 点击 2025-06-11 12:01
 搜索
搜索
大幅缓解LLM偏科,只需调整SFT训练集的组成。
「尽管经过 SFT 的模型可能看起来在进行推理,但它们的行为更接近于模式模仿 —— 一种缺乏泛化推理能力的伪推理形式。」

本文深入梳理了围绕DeepSeek-R1展开的多项复现研究,系统解析了监督微调(SFT)、强化学习(RL)以及奖励机制、数据构建等关键技术细节。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。
基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。

让大语言模型更懂特定领域知识,有新招了!

在面对复杂的推理任务时,SFT往往让大模型显得力不从心。最近,CMU等机构的华人团队提出了「批判性微调」(CFT)方法,仅在 50K 样本上训练,就在大多数基准测试中优于使用超过200万个样本的强化学习方法。
回顾 AGI 的爆发,从最初的 pre-training (model/data) scaling,到 post-training (SFT/RLHF) scaling,再到 reasoning (RL) scaling,找到正确的 scaling 维度始终是问题的本质。
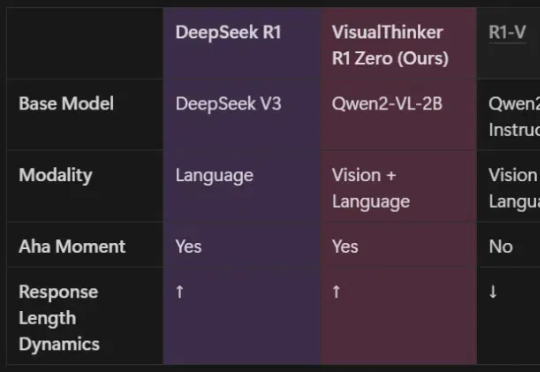
由UCLA等机构共同组建的研究团队,全球首次在20亿参数非SFT模型上,成功实现了多模态推理的DeepSeek-R1「啊哈时刻」!就在刚刚,我们在未经监督微调的2B模型上,见证了基于DeepSeek-R1-Zero方法的视觉推理「啊哈时刻」!
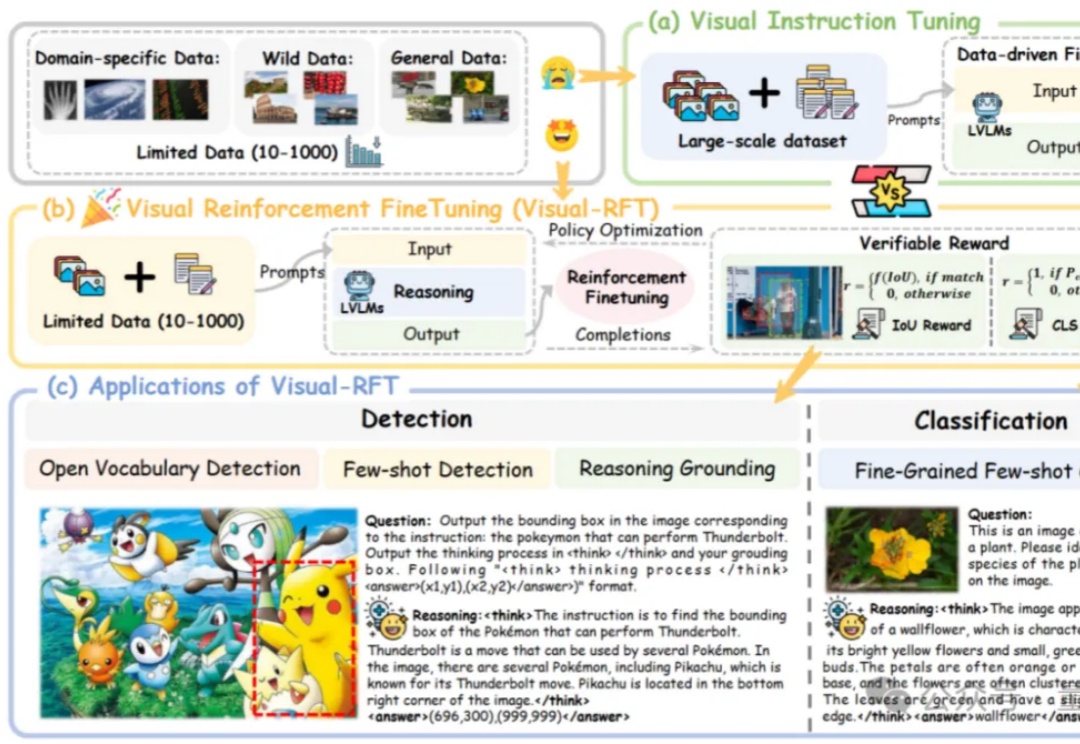
o1/DeepSeek-R1背后秘诀也能扩展到多模态了!