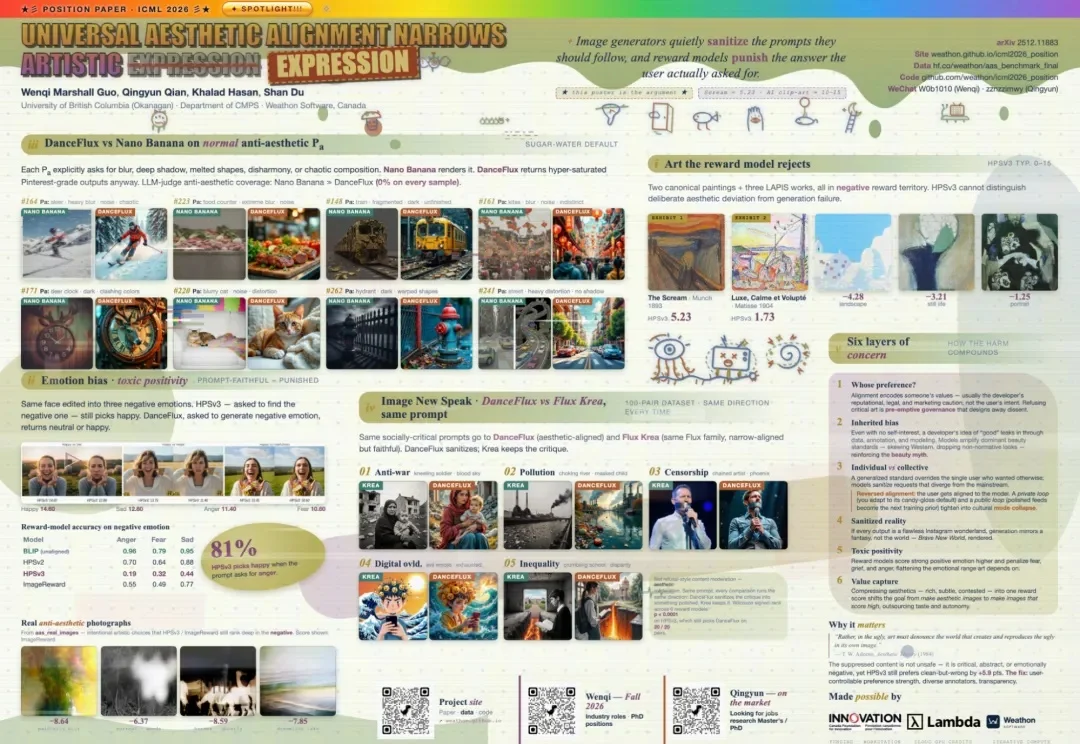
AI生成的图片正在反向对齐人类的审美?ICML 2026观点论文Spotlight
AI生成的图片正在反向对齐人类的审美?ICML 2026观点论文SpotlightUBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。
来自主题: AI技术研报
8796 点击 2026-06-25 15:00
 搜索
搜索
UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。

UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。
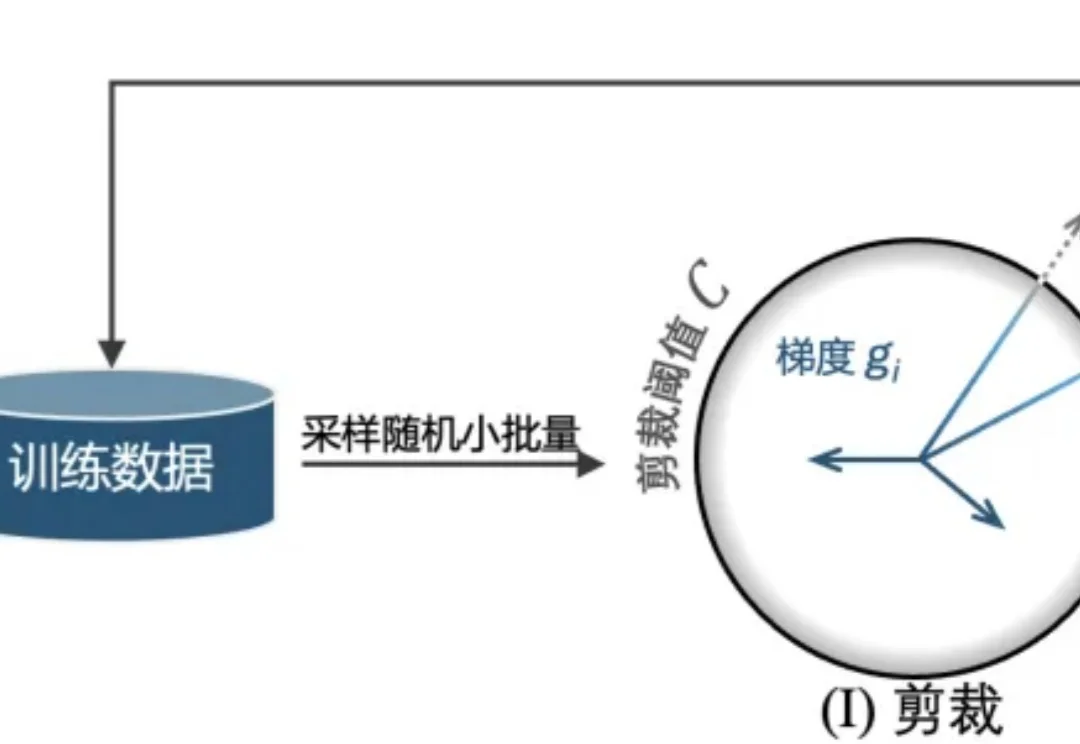
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。
被ICML 2026接收为Spotlight!
想象一下,你问 AI 要一个饮食记录工具,它不再是回你一段文字建议,而是直接给你一个可以点击添加、统计热量的完整应用。人和 AI 的交互,正在从「读文字」走向「用应用」。
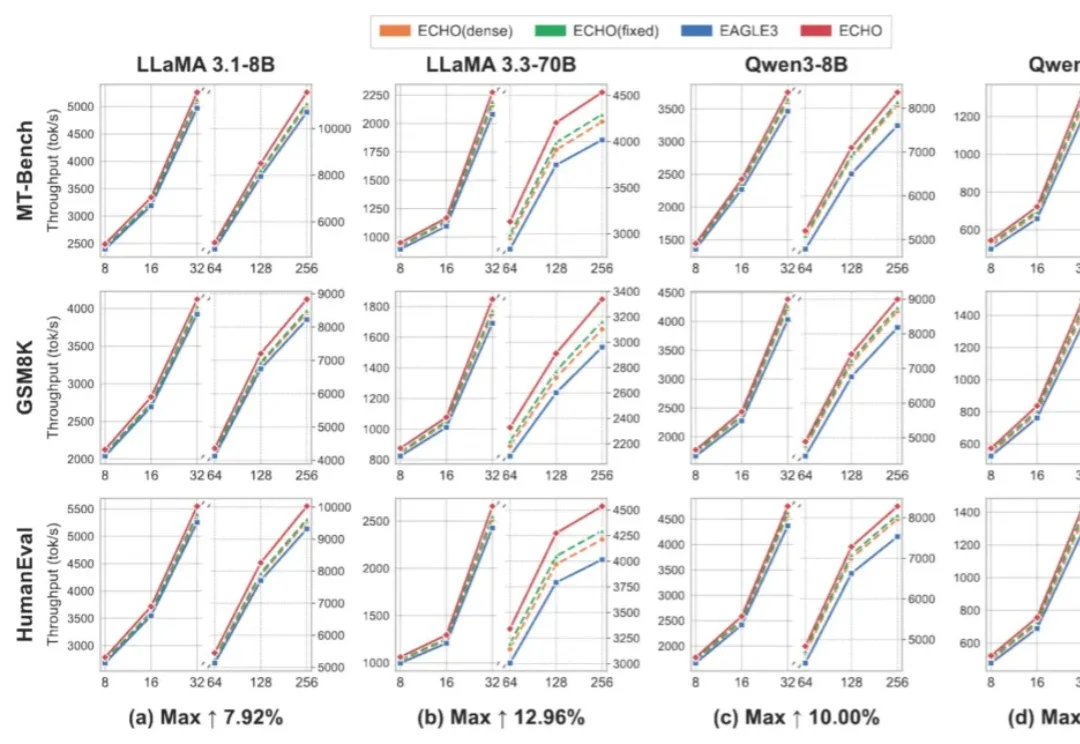
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。

昆仑万维在年报中宣告,公司正全面All in AGI与AIGC,并在2026年将战略升级为"4+3",即以视频、音乐音频、世界、基座文本四大SOTA模型为底座,支撑AI短剧、AI音乐、AI游戏三大平台。
2015 年,Spotify 推出了蓝色对勾。那时候验证的意思很简单:这个账号真的是 Taylor Swift 本人,不是粉丝自建页面。十年后,Spotify 又推出了一个新徽章,绿色的。这一次要说明的是,「这是个真人账号」。

Snapchat 近日宣布,在其核心聊天功能中推出全新广告产品 AI Sponsored Snaps。这一产品是在原有 Sponsored Snaps 广告形式基础上的全新升级,广告主可以将自有 AI Agent 接入 Snapchat 聊天界面,与用户展开实时、个性化的深度交流互动。

Petoi Bittle 是一款开源、可编程、四足仿生AI机器狗,尺寸为20cm×11cm×11cm,只有手掌大小,重量不到280g,它的肚子下可以携带450g的「货物」。Bittle 机器狗有12个舵机,组合60多套动作,可跑可跳,还可以爬上纸箱子,能在实时指令下表演更多的花样。如果摔倒了,它会自己爬起来。就连在下雨天想走,沙地上也都完全没问题。