ICCV 2025 | 清华&腾讯混元X发现「视觉头」机制:仅5%注意力头负责多模态视觉理解
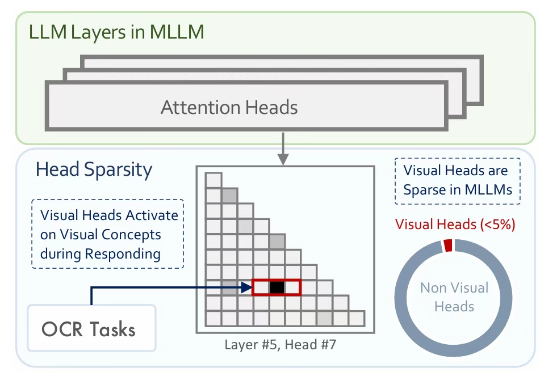
ICCV 2025 | 清华&腾讯混元X发现「视觉头」机制:仅5%注意力头负责多模态视觉理解多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。
来自主题: AI技术研报
8343 点击 2025-07-15 10:07
 搜索
搜索
多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。