32B逆袭GPT-5.2:首个端到端GPU编程智能体框架StitchCUDA问世
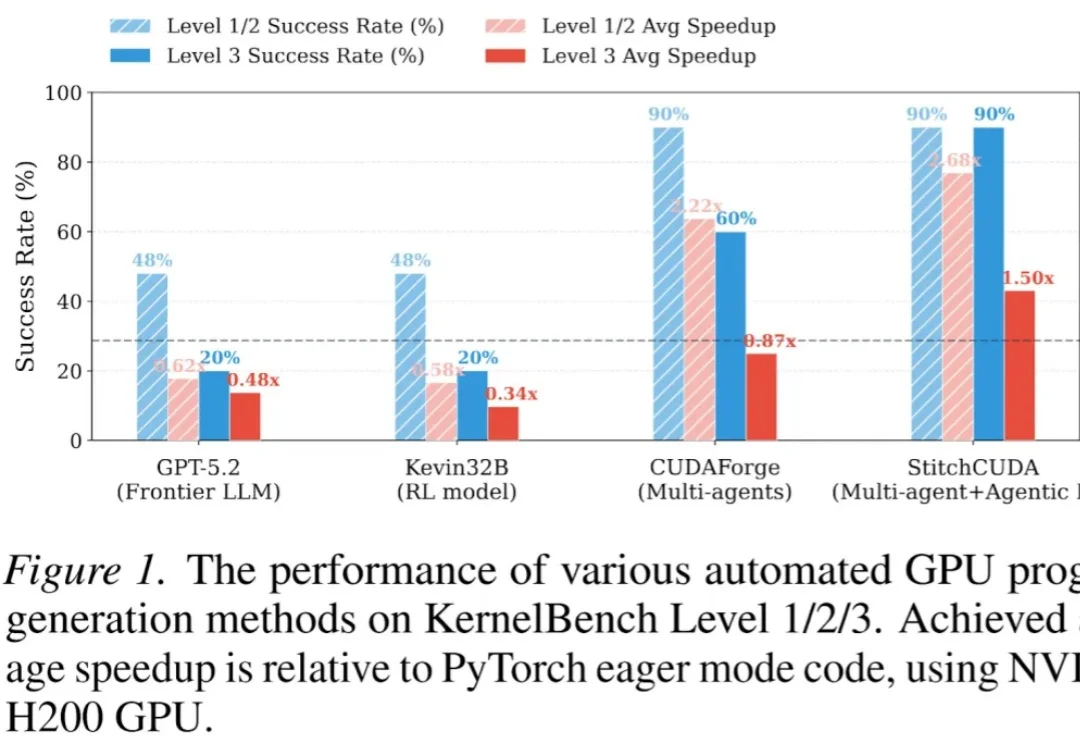
32B逆袭GPT-5.2:首个端到端GPU编程智能体框架StitchCUDA问世现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
来自主题: AI技术研报
8572 点击 2026-03-05 14:28
 搜索
搜索
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。