只看图片就能学会压缩Token!浙大&阿里新框架多轮VQA压缩率90%,精度不掉|CVPR 2026
只看图片就能学会压缩Token!浙大&阿里新框架多轮VQA压缩率90%,精度不掉|CVPR 2026多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。
来自主题: AI技术研报
8646 点击 2026-05-08 09:52
 搜索
搜索
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。
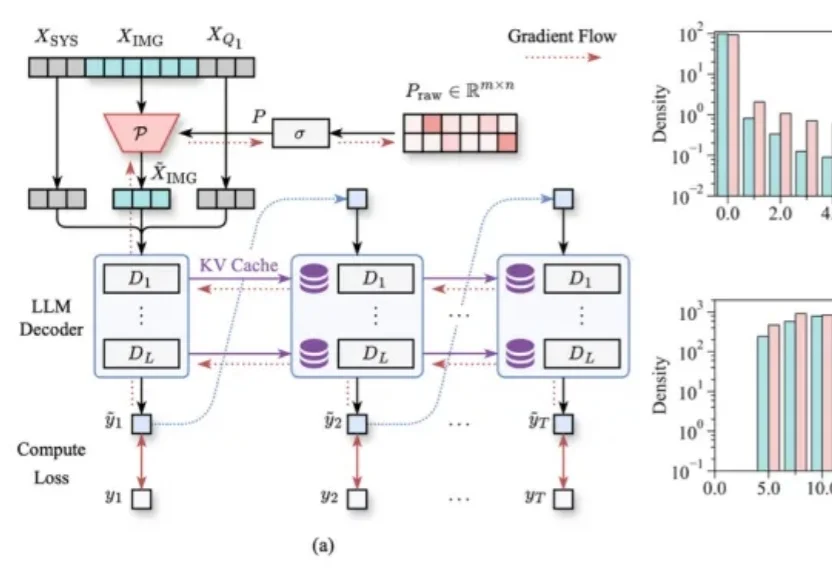
近年来多模态大模型在视觉感知,长视频问答等方面涌现出了强劲的性能,但是这种跨模态融合也带来了巨大的计算成本。高分辨率图像和长视频会产生成千上万个视觉 token ,带来极高的显存占用和延迟,限制了模型的可扩展性和本地部署。

Hi,早上好。 我是洛小山,和你聊聊 AI 应用的降本增效。

大模型一个token一个token生成,效率太低怎么办?
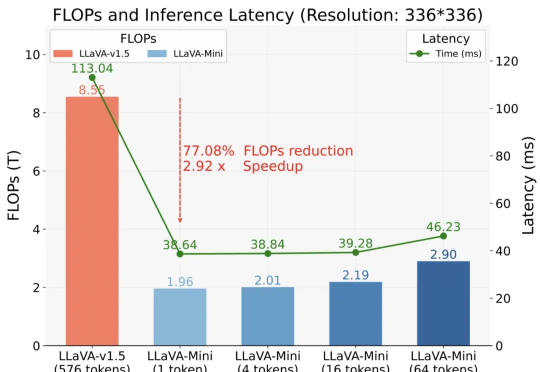
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。