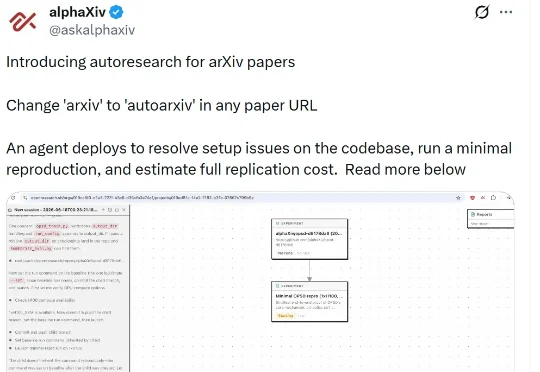
哈?改个URL就行!alphaXiv甩出论文复现神器,单卡也能跑
哈?改个URL就行!alphaXiv甩出论文复现神器,单卡也能跑机器之心编辑部 AI 读论文这件事,正在进入下一个阶段。 最近,alphaXiv 推出了一个面向 arXiv 论文的 autoresearch 功能。 它的使用方式非常直接:当用户看到一篇论文时,只需要把论文 URL 里的「arxiv」改成「autoarxiv」,系统就会:
来自主题: AI资讯
8278 点击 2026-06-20 20:19
 搜索
搜索
机器之心编辑部 AI 读论文这件事,正在进入下一个阶段。 最近,alphaXiv 推出了一个面向 arXiv 论文的 autoresearch 功能。 它的使用方式非常直接:当用户看到一篇论文时,只需要把论文 URL 里的「arxiv」改成「autoarxiv」,系统就会:

谷歌DeepMind宣布:AGI,已经过时了!就在最近,谷歌DeepMind出了一份干货满满的57页报告,标题只有四个词:《从AGI到ASI》。论文地址:https://arxiv.org/abs/2606.12683

自今年2月以来,AxiomProver已让8篇覆盖最硬核领域的AI论文现身arXiv,6篇正在筹备。上午出题下午交卷的节奏,让博士生秃头、教授评职称的日子一去不复返。接下来AI能做到什么?

最近,来自上海创智学院、复旦大学等机构的研究者提出了 Hallo-Live,试图正面解决这个矛盾。论文于 2026 年 4 月 26 日 发布在 arXiv。该方法将 异步双流扩散(Asynchronous Dual-Stream Diffusion) 与 人类偏好引导蒸馏(Human-Centric Preference-Guided DMD) 结合起来
每次想让AI读个外部网站的信息,看到这句话头都要炸了。不过,GitHub有个开源项目OpenCLI把这事儿解决了:网站变命令行。Reddit讨论、B站热门、Arxiv论文,以前开浏览器一个个翻的东西,现在终端一行命令直接出结构化数据。

今天凌晨,俄勒冈州立大学杰出教授(荣休)、arXiv 计算机科学分区 CoRR 的机器学习板块首席版主 Thomas G. Dietterich 宣布:根据我们的行为准则,在论文上署名即表示每位作者对其全部内容承担完全责任,无论这些内容是如何生成的。
现象级AI视频技术、字节Seedance 2.0在arXiv发论文了。晒了26页的Benchmark,和贡献者名单。170位团队成员全公开,署名和尊重都拉满了,不过嘛这就不怕……嘛?
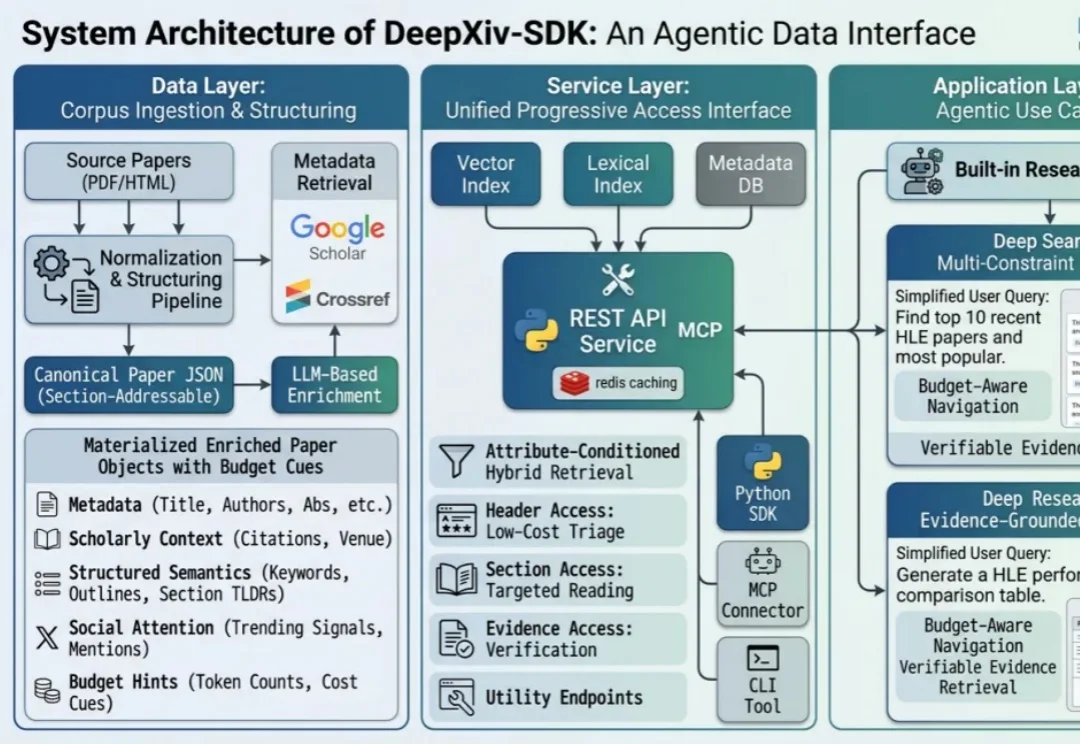
DeepXiv 是专为智能体设计的科技文献基础设施,把论文搜索、渐进式阅读、热点追踪和深度调研变成可调用、可编排、可自动化的能力。

UIUC研究团队打造ResearchArcade,将ArXiv论文、OpenReview评审、图表代码等碎片数据连接成动态知识图谱。模型可直接学习引用关系、修改轨迹与审稿互动,让AI更好辅助科研写作、修订与预测,为下一代科研智能体奠定统一数据基础。

刚刚,Nature报道了一项关于AI“水论文”的新研究,牵头人之一,正是arXiv创始人Paul Ginsparg。老板亲自下场的原因很简单,就是这几年arXiv投稿量激增,导致系统不堪重负,而罪魁祸首很可能就是AI。