
上海大模型龙头MiniMax,启动A股上市!
上海大模型龙头MiniMax,启动A股上市!证监会官网显示,上海AI大模型龙头企业MiniMax已于5月29日向上海证监局提交了上市辅导备案报告,开启A股上市进程,中信证券担任辅导机构。这也意味着,MiniMax将与已经提交A股上市辅导备案的智谱,一同冲刺A股大模型第一股。
来自主题: AI资讯
9259 点击 2026-05-30 10:55
 搜索
搜索
证监会官网显示,上海AI大模型龙头企业MiniMax已于5月29日向上海证监局提交了上市辅导备案报告,开启A股上市进程,中信证券担任辅导机构。这也意味着,MiniMax将与已经提交A股上市辅导备案的智谱,一同冲刺A股大模型第一股。
DeepSeek研究员陈德里,在个人博客更新一篇研究综述论文。用的是他自己的技能DeliAutoResearch,DeepSeek-V4-Pro研究和写作,GPT-Image2画图。论文共迭代6次(V1:4 次,V2:1 次,V3:1 次),总耗时6天,进行了约108轮Agent调用,消耗64.8万token,写了2234行LaTeX代码。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。
灰度一个月,这个数字让我们有点坐不住——它说明大家对"让AI用我的知识替我干活"这件事,等不及了。好消息是,从今天起,所有人打开 ima,都可以直接使用copilot。同时,ima知识号也开始能发布 Skill 了,知识广场从“内容平台”延伸为“能力平台”。

智象未来正式发布基于新一代原生全模态模型架构 Unified Transformer(UiT)打造的图像大模型 HiDream-O1-Image-Pro。这一超2千亿参数的原生全模态图像大模型,不仅在多个基准测试中刷新 SOTA 纪录,也标志着智象未来正向图像、视频、文本、音频等多模态统一建模的“原生全模态”阶段迈进。
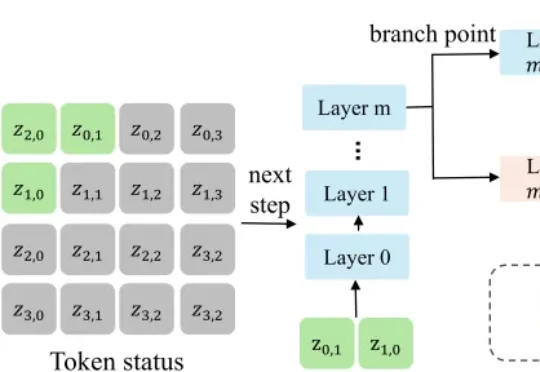
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR—— 一个轻量级的后训练加速框架。不需要从头训练,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍的端到端加速。

从Atari到AlphaGo,从AlphaStar到SIMA,DeepMind用游戏做AI研究已走过十余年,每换一个战场,研究问题就升一个量级。这一次的战场是EVE Online:一个跑了23年、从未重置的活宇宙。

李飞飞团队最新发布ESI-Bench——一个专门用来评测具身空间智能的新基准。过去的空间智能评测默认给模型最优观测,而ESI-Bench第一个把观察者变成行动者,闭合了感知-行动回路。

Sam Altman 今天在 X 上扔出一个数字:ChatGPT Images 2.0 在印度已经生成超过 10 亿张图。距离产品发布只有 27 天。TechCrunch 和第三方数据验证了印度确实是最大市场——但全球增长远没有那么均匀,这更像一场区域性起飞。

近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。