
ICLR 2026|美图提出位置编码场 PE-Field ,让 DiT 感知和控制 3D 空间
ICLR 2026|美图提出位置编码场 PE-Field ,让 DiT 感知和控制 3D 空间PE-Field将传统的2D位置编码扩展为结构化的3D场,使DiT能够更加直接地在3D空间中处理几何信息。
来自主题: AI技术研报
6433 点击 2026-06-16 09:52
 搜索
搜索
PE-Field将传统的2D位置编码扩展为结构化的3D场,使DiT能够更加直接地在3D空间中处理几何信息。

ICLR'26新研究CPiRi打破时序预测僵局:用冻结底座提取时序特征,轻量模块专注学习通道间真实关系,不靠位置编码「背答案」。测试中通道乱序性能零波动,仅用25%数据即可泛化至全网络,真正实现鲁棒与精准双赢。
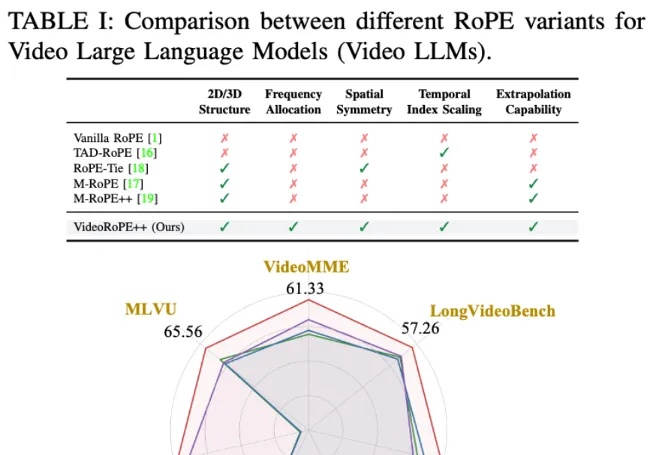
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。
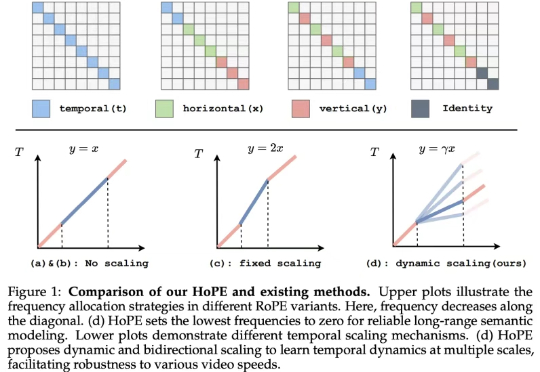
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。
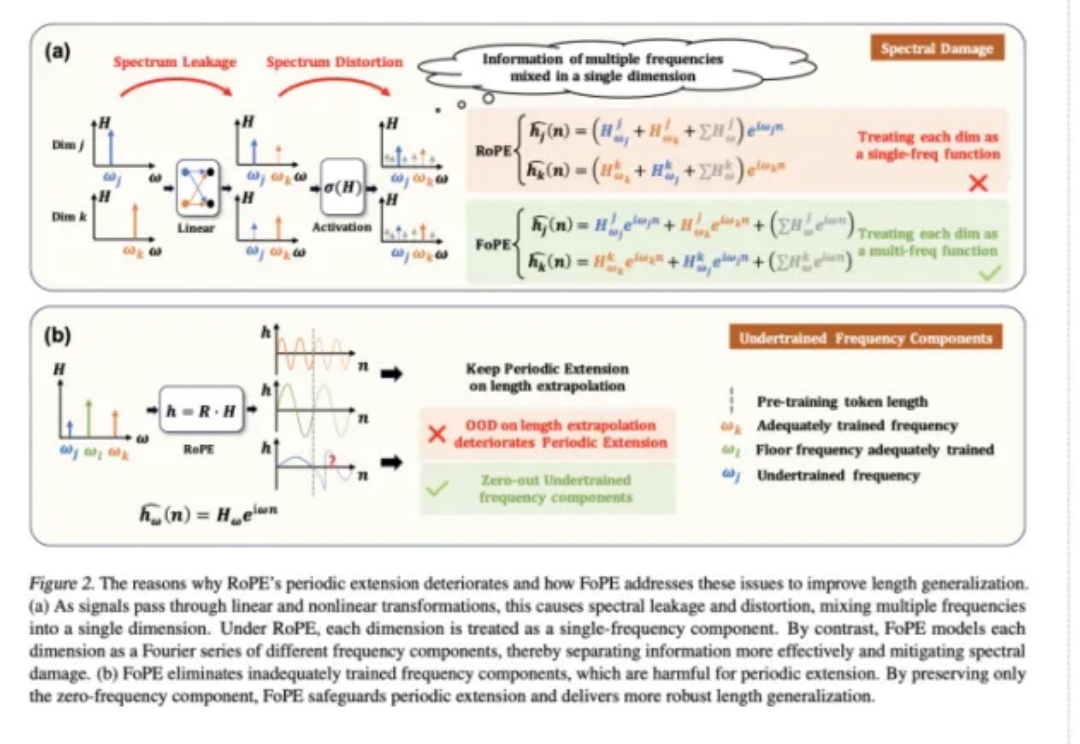
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。
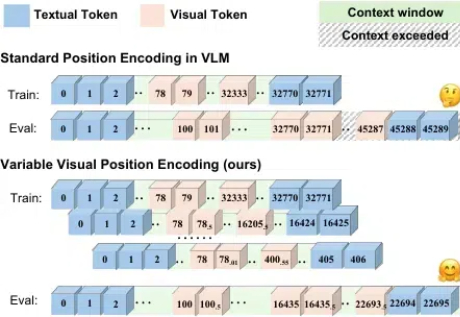
随着语言大模型的成功,视觉 - 语言多模态大模型 (Vision-Language Multimodal Models, 简写为 VLMs) 发展迅速,但在长上下文场景下表现却不尽如人意,这一问题严重制约了多模态模型在实际应用中的潜力。
一个有效的复杂系统总是从一个有效的简单系统演化而来的。——John Gall

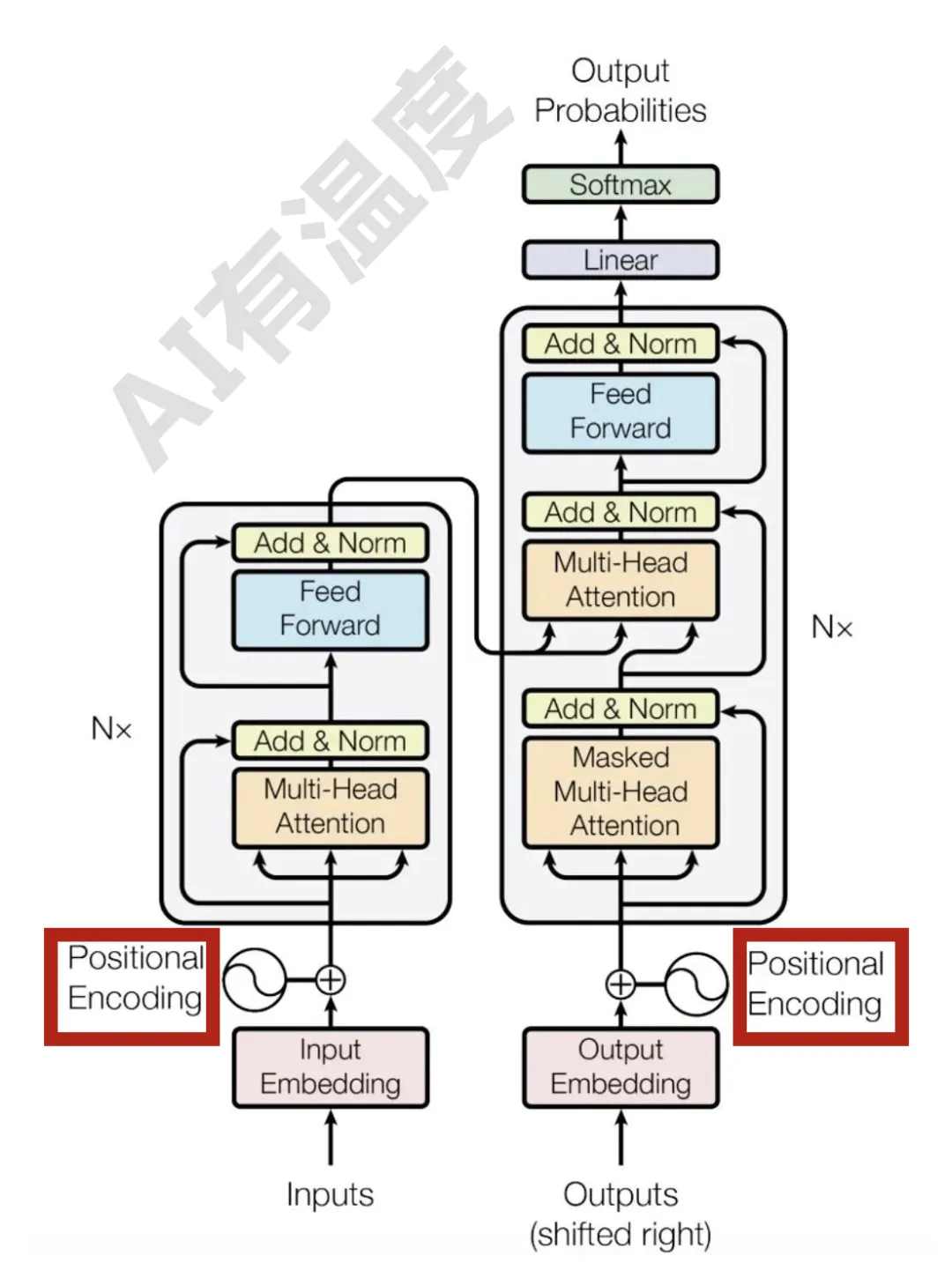
在当今的人工智能领域,Transformer 模型已成为解决诸多自然语言处理任务的核心。然而,Transformer 模型在处理长文本时常常遇到性能瓶颈。传统的位置编码方法,如绝对位置编码(APE)和相对位置编码(RPE),虽然在许多任务中表现良好,但其固定性限制了其在处理超长文本时的适应性和灵活性。
RNN每个step的隐状态都取决于上一个step的输出,这种连续的状态转移方式使得RNN天然带有位置信息。

在自然语言处理(Natural Language Processing,NLP)领域,Transformer 模型因其在序列建模中的卓越性能而受到广泛关注。