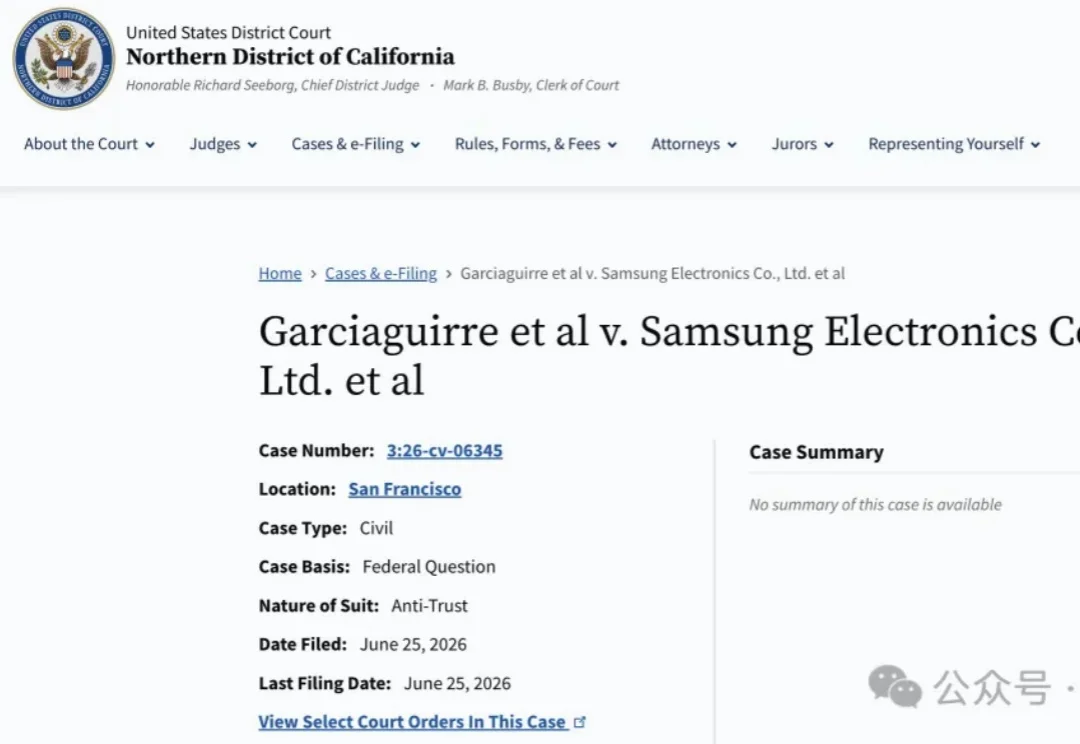
三星、sk海力士、美光存储三巨头集体被起诉
三星、sk海力士、美光存储三巨头集体被起诉苹果涨价,你可能骂错人了。
来自主题: AI资讯
10033 点击 2026-06-30 15:11
 搜索
搜索
苹果涨价,你可能骂错人了。

刚刚,谷歌DeepMind发布了Gemma 4 12B。一句话概括这个模型的定位:把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。它填补的是Gemma家族里一个关键空缺:比边缘端的E4B更强,比26B混合专家模型(MoE)更轻。而且在整个Gemma 4系列里,它是第一个支持原生音频输入的中等规模模型。

AI火,能理解,说算力很缺,也可以理解,然后内存不够了,能源不够了,通信带宽不够了,感觉AI产业链上的每个环节最近都在挨个成为短板和热点,散户们也在一轮又一轮地对着行情研究前沿技术。

当所有人都在盯着 GPU,真正卡住 AI 脖子的,是另一块芯片。

一个 8B 参数的大模型,通常需要约 16GB 显存。参数越多,越吃显存,这就是为什么,内存价格一天比一天高。

刚刚的,面壁智能联合 OpenBMB 搞了个端侧开源周。今天作为开源周的第一天,端出来的是个好东西 BitCPM-CANN,模型权重只需要约 200 MB 的内存,手表也够跑
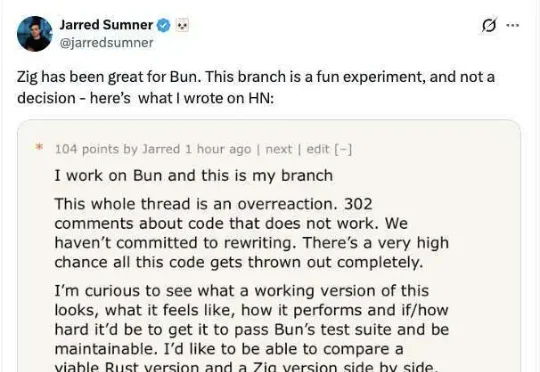
这场从 Zig 到 Rust 的迁移,实际上只花了大约六天,涉及 96 万行代码,并且在 Linux x64 glibc 环境下通过了现有测试套件的 99.8%。而六天前,Jarred 还在 Hacker News 上说 这是一堆根本还跑不起来的代码,“最后被全Ω部扔掉的概率非常高”。六天后,同样的代码变成了“Zig 的最后一个版本”。

英伟达副总裁亲口承认AI算力账单超过员工工资。所有人都在抱怨AI贵,但很少有人追问一句:这些钱最后流到了哪里?一个答案是韩国。SK海力士Q1利润率72%;三星电子市值突破1万亿美元。这场盛宴的脚本,已经写到了2029年。
前几天在 Milvus 社区,一位做以图搜图的朋友提了一个问题:

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。