
华为具身大脑一号位朱森华创业,具脑磐石获亿元级融资,用认知科学造世界模型
华为具身大脑一号位朱森华创业,具脑磐石获亿元级融资,用认知科学造世界模型刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。
来自主题: AI资讯
8888 点击 2026-05-25 10:27
 搜索
搜索
刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。
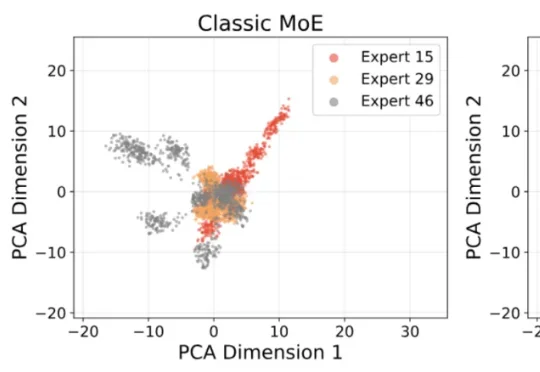
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。

创始人杨昌鹏曾任华为云媒体创新 Lab 首任主任、交互式媒体方向 1 号位。

5 月 20 日,具身智能初创公司贝塔无限(Beta Infinity)宣布完成种子+ 轮融资。本轮由世纪华通参与的盛趣泰和基金与和利资本联合领投,毅达资本、南山战新投等机构跟投。这是该公司成立后完成的第二轮融资,累计融资金额达数亿元,资金将主要用于核心技术研发及产品试制等。

AI shopping 的热度正在升温。
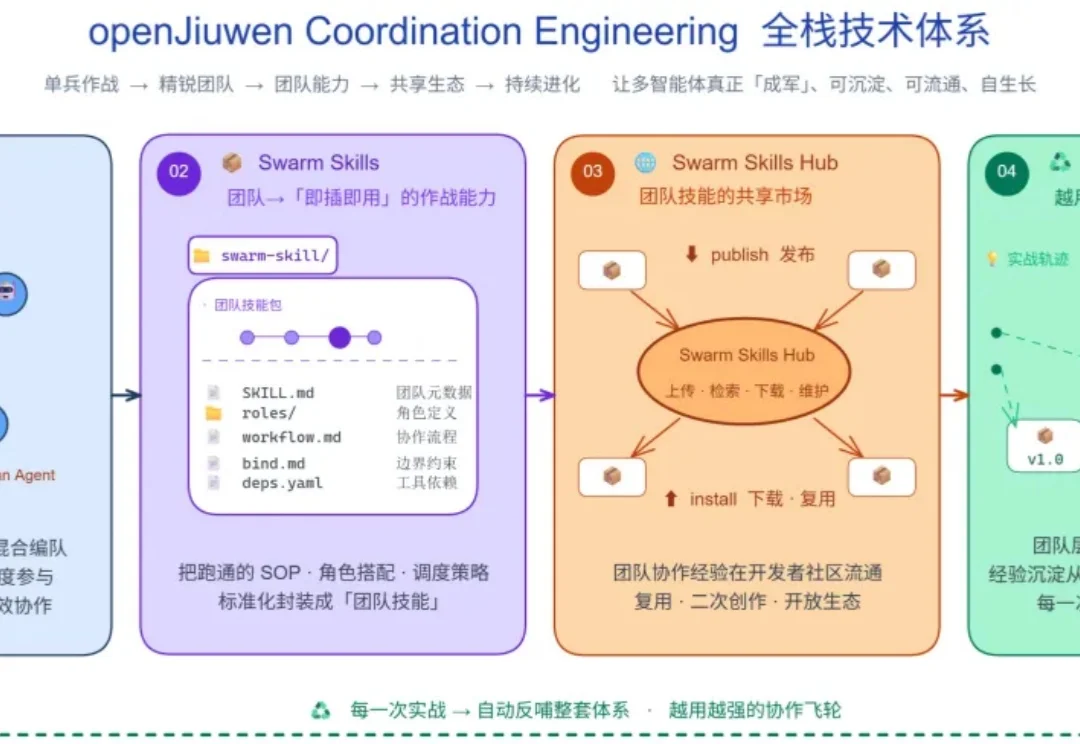
刚刚,华为支持的开源 AI Agent 平台社区 openJiuwen 发布并开源了蜂群智能体 JiuwenSwarm。
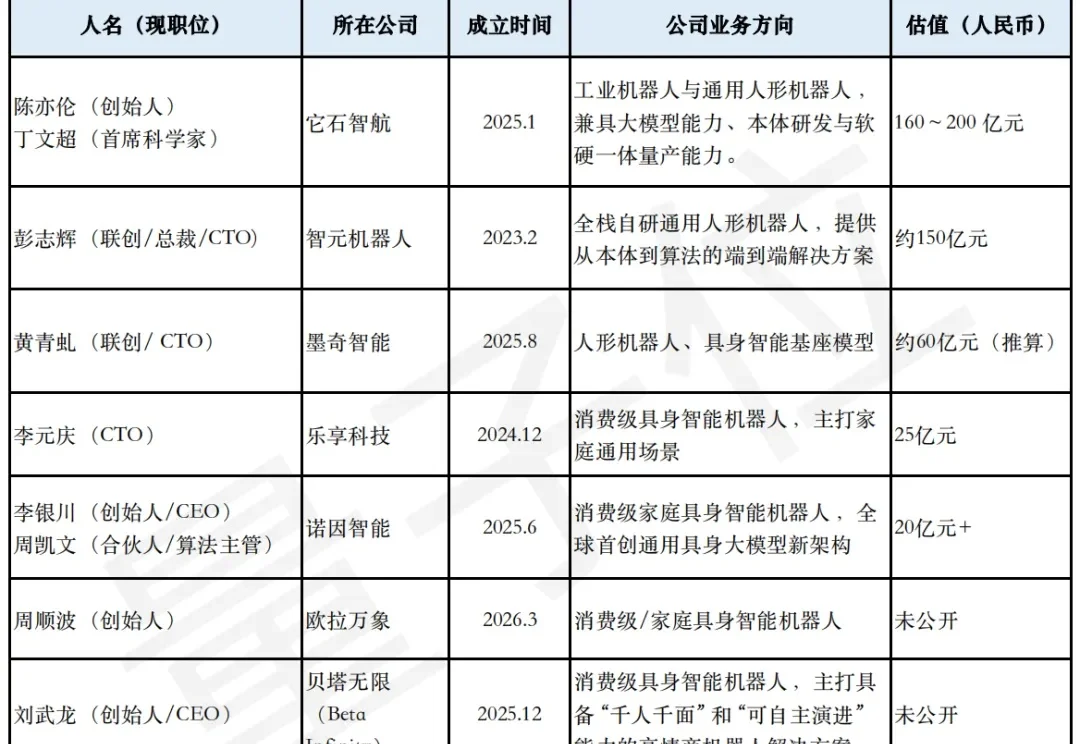
中国具身智能赛道,最近出现了一个越来越清晰的现象。
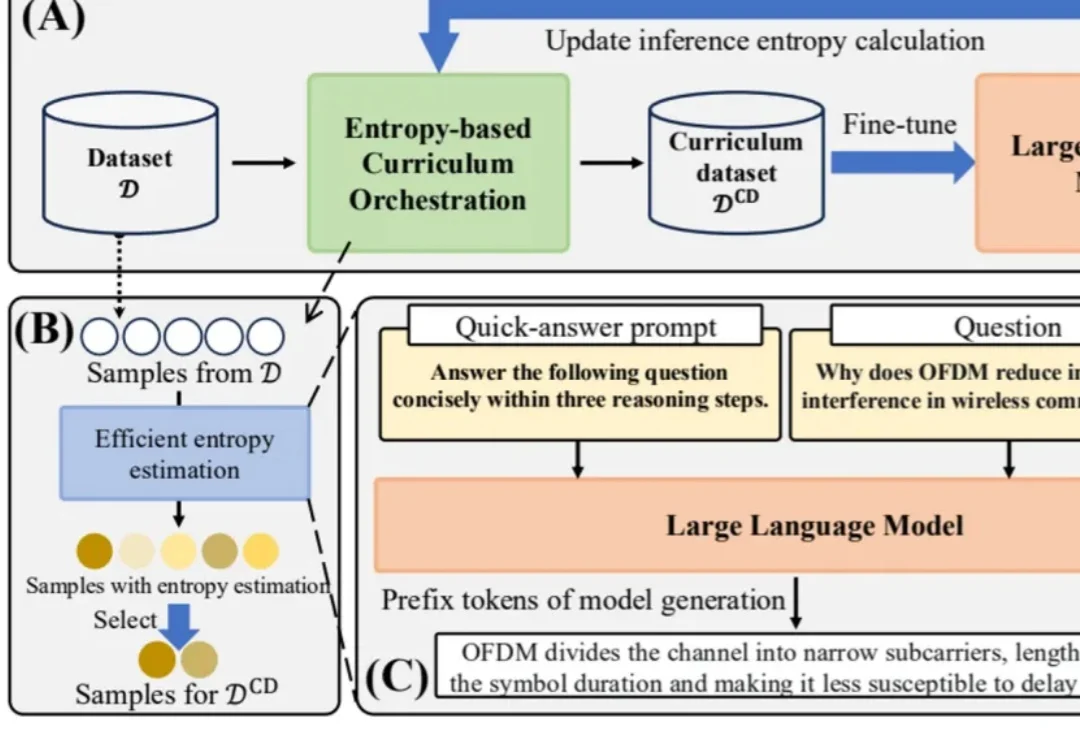
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。

华为联合新加坡国立大学和中国科学技术大学研究人员提出 QuantClaw。这是一款面向 OpenClaw 的即插即用动态模型精度路由插件,基于大规模低精度量化实证研究,让模型精度成为可动态分配的资源,实现服务质量不降反升、成本下降、延迟降低的三重收益。
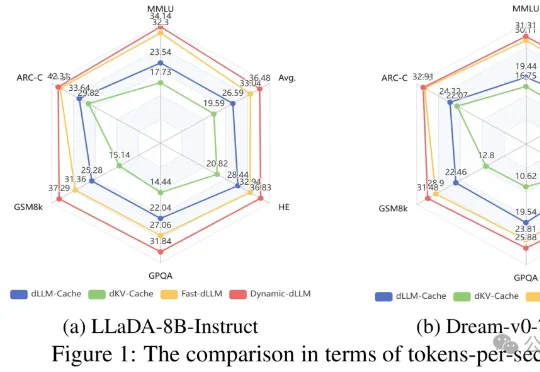
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。