
从第一性原理看机器人AI:为什么它比大模型更难?
从第一性原理看机器人AI:为什么它比大模型更难?这篇来自 Interlatent(一家聚焦具身智能后训练与部署的早期创业公司) 的文章,试图从第一性原理出发,把现代 AI 机器人技术重新讲清楚:一个机器人到底如何理解世界,如何生成动作,又为什么会在数据、延迟和泛化上遇到如此多的困难。
来自主题: AI技术研报
7342 点击 2026-06-29 09:15
 搜索
搜索
这篇来自 Interlatent(一家聚焦具身智能后训练与部署的早期创业公司) 的文章,试图从第一性原理出发,把现代 AI 机器人技术重新讲清楚:一个机器人到底如何理解世界,如何生成动作,又为什么会在数据、延迟和泛化上遇到如此多的困难。

来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。
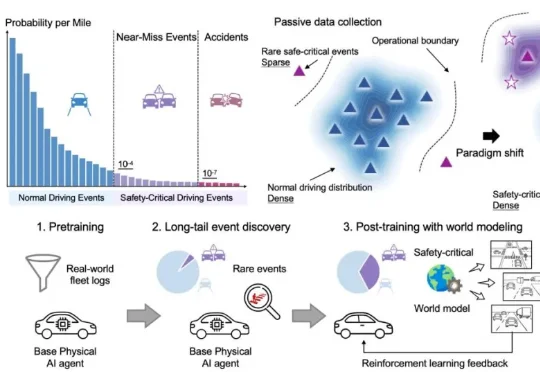
香港大学李弘扬团队联合华为、上海创智学院及清华大学李升波教授团队,发表的最新论文World Engine: Towards the Era of Post-Training for Autonomous Driving给出了系统回答。
本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

最近,前沿实验室 Mind Lab 密集发布了一系列关于 LoRA 与 PEFT(高效微调)的研究结果,似乎描绘出了另一条大模型「持续学习」的路径。在 Mind Lab 的视角中,PEFT 不再是对大模型全参数后训练的一种廉价平替,更是实现从 “基础模型” 向 “可持续学习智能体” 过渡的核心架构机制。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

近期,深圳河套学院(SLAI)AI训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)团队与深智城AI算力平台,仅用1个月,共同基于昇腾910C国产算力集群实现DeepSeek-V4-Pro全参数续训练/SFT稳定运行,完成长稳训练1500+步,训练MFU超30%,关键训练算子效率提升14%。

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。