商汤SenseNova U1深度拆解,原生统一架构终结缝合时代
商汤SenseNova U1深度拆解,原生统一架构终结缝合时代当 AI 行业的目光集中在 Agent、工具调用、长程任务这些上层应用之时,底层的多模态架构正在经历一次更安静、也更彻底的范式转变 —— 它要回答的是一个看似朴素的问题:理解与生成,是否天生就该是两件事?
来自主题: AI技术研报
7324 点击 2026-05-15 10:36
 搜索
搜索
当 AI 行业的目光集中在 Agent、工具调用、长程任务这些上层应用之时,底层的多模态架构正在经历一次更安静、也更彻底的范式转变 —— 它要回答的是一个看似朴素的问题:理解与生成,是否天生就该是两件事?
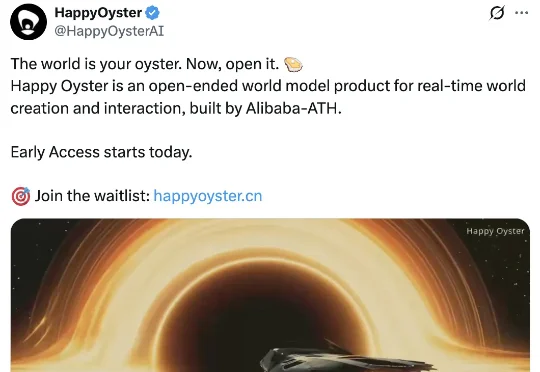
就在刚刚,成立恰满一个月的阿里ATH(Alibaba Token Hub)事业群,发布全球首个主动式实时交互的世界模型产品。名也挺有趣的,叫HappyOyster(快乐生蚝)。HappyOyster搭载原生多模态架构,背后是支持多模态输入与音视频联合生成的流式生成世界模型,核心主打漫游(Wander)、导演(Direct)、创造(Create)、分享(Share)。

全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。

视觉数据的种类极其多样,囊括像素级别的图标到数小时的视频。现有的多模态大语言模型(MLLM)通常将视觉输入进行分辨率的标准化或进行动态切分等操作,以便视觉编码器处理。然而,这些方法对多模态理解并不理想,在处理不同长度的视觉输入时效率较低。