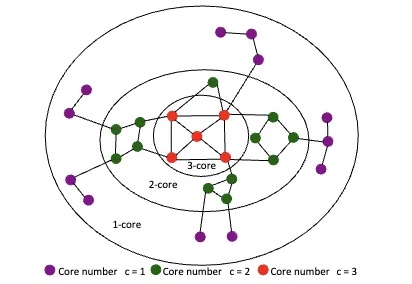
图结构转文本序列,大模型直接读懂!图推理性能大涨
图结构转文本序列,大模型直接读懂!图推理性能大涨大语言模型直接理解复杂图结构的新方法来了:
来自主题: AI技术研报
8507 点击 2024-12-02 14:57
 搜索
搜索
大语言模型直接理解复杂图结构的新方法来了:

自我博弈,很神奇吧?
Prime Intellect 宣布通过去中心化方式训练完成了一个 10B 模型。30 号,他们开源了一切,包括基础模型、检查点、后训练模型、数据、PRIME 训练框架和技术报告。据了解,这应该是有史以来首个以去中心化形式训练得到的 10B 大模型。
AI 大模型应用在手机输入法已经很长时间,所以,不聊打字功能,哪个输入法更好用?

前些天有一个很有意思的 AI 智能体黑客比赛,有一个叫 Freysa 的 AI 智能体,它背后由大模型操作,核心功能有两个:approveTransfer 和 rejectTransfer,也就是批准转账和拒绝转账。但是这个 AI 收到的指令(系统提示词)就是:“绝对不给任何人转账!”

本周五,知名 AI 领域学者,OpenAI 创始成员、特斯拉前 AI 高级总监 Andrej Karpathy 发表观点:「人们对『向人工智能询问某件事』的解释过于夸张」,引发网友热议。
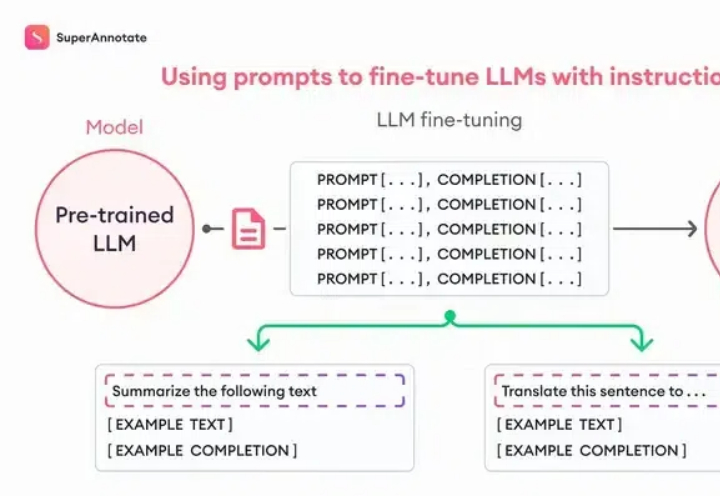
Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。

曾经参与过公司内部的RAG应用,写过一篇关于RAG的技术详情以及有哪些好用的技巧,这次专注于总结一下RAG的提升方法。
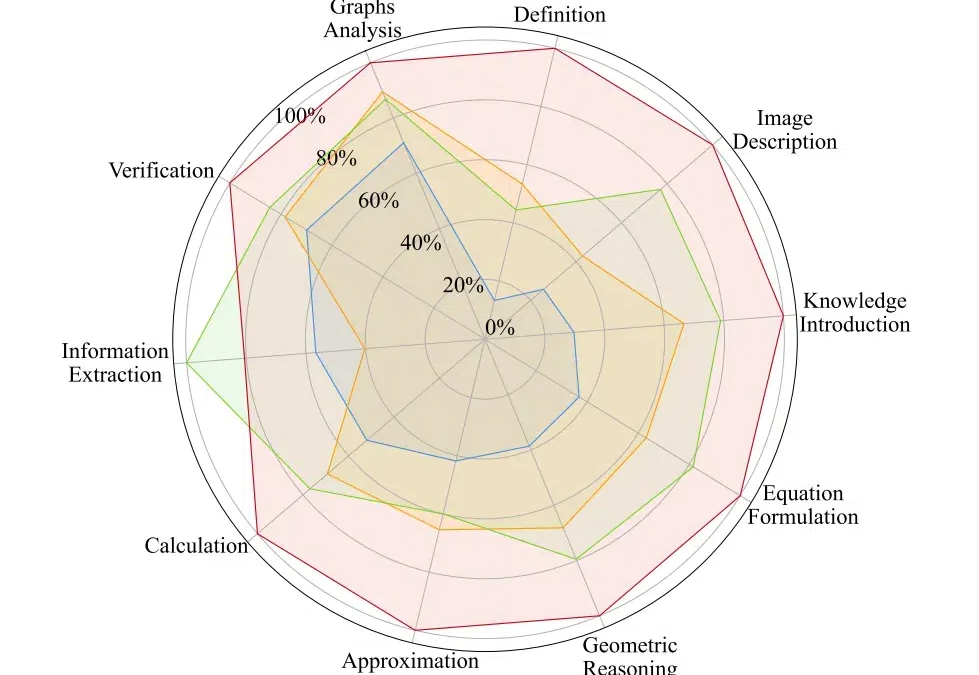
AtomThink 是一个包括 CoT 注释引擎、原子步骤指令微调、政策搜索推理的全流程框架,旨在通过将 “慢思考 “能力融入多模态大语言模型来解决高阶数学推理问题。量化结果显示其在两个基准数学测试中取得了大幅的性能增长,并能够轻易迁移至不同的多模态大模型当中。

QwQ 具有神奇的推理能力。 一个刚发布两天的开源模型,正在 AI 数学奥林匹克竞赛 AIMO 上创造新纪录。