
从图像到视频的任意分割:X2SAM让MLLM 真正看懂像素级时空世界
从图像到视频的任意分割:X2SAM让MLLM 真正看懂像素级时空世界为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。
来自主题: AI技术研报
7949 点击 2026-05-16 10:50
 搜索
搜索
为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。

麻省理工学院最新研究预示着人类距离能够自主学习的AI又迈出了关键一步。该研究推出了一种全新的自适应大模型框架「SEAL」,让模型从「被动学习者」变为「主动进化者」。

北京深度逻辑智能科技有限公司推出了 LLaSO—— 首个完全开放、端到端的语音语言模型研究框架。LLaSO 旨在为整个社区提供一个统一、透明且可复现的基础设施,其贡献是 “全家桶” 式的,包含了一整套开源的数据、基准和模型,希望以此加速 LSLM 领域的社区驱动式创新。
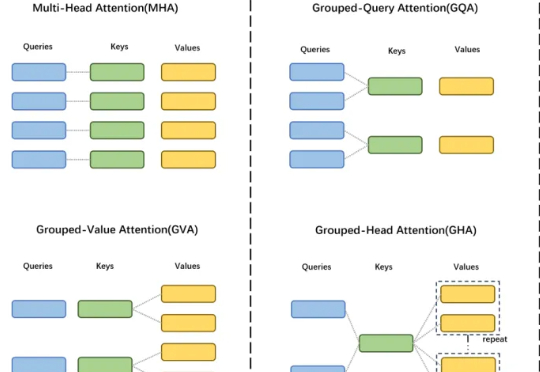
GTA 工作由中国科学院自动化研究所、伦敦大学学院及香港科技大学(广州)联合研发,提出了一种高效的大模型框架,显著提升模型性能与计算效率。
Mac用户,终于不用羡慕N卡玩家有专属大模型Chat with RTX了!

在自然语言处理(Natural Language Processing,NLP)领域,Transformer 模型因其在序列建模中的卓越性能而受到广泛关注。

在Transformer占据多模态工具半壁江山的时代,大核CNN又“杀了回来”,成为了一匹新的黑马。