
深度|ARR过亿美金AI招聘00后创始人:未来最有价值的是拥有“反常识性观点”和“品味”的人,人们最应该优化自己的适应性
深度|ARR过亿美金AI招聘00后创始人:未来最有价值的是拥有“反常识性观点”和“品味”的人,人们最应该优化自己的适应性人类数据市场正经历一次巨大变革。这个市场原来是众包模式,即找很多低中技能的人员为早期ChatGPT那种模型写些语法勉强正确的句子。
来自主题: AI资讯
8981 点击 2025-04-26 15:49
 搜索
搜索
人类数据市场正经历一次巨大变革。这个市场原来是众包模式,即找很多低中技能的人员为早期ChatGPT那种模型写些语法勉强正确的句子。
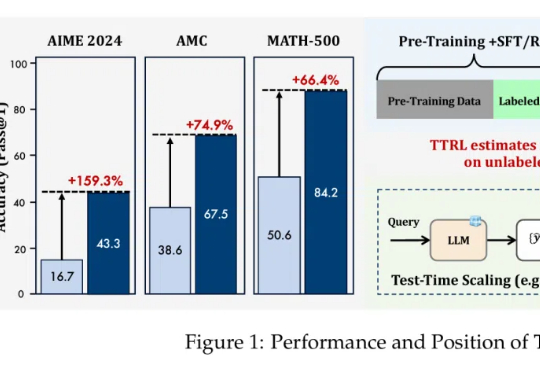
近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。

在大量桌面研究、调研访问、数据分析之后,为了更好把握空间智能现状和未来发展方向,量子位智库在《空间智能研究报告》(以下简称《报告》)中回答如上问题,同时系统性梳理了各应用领域重要玩家,并对产业迭代影响要素作出研判。
2025,随着大语言模型技术的迅猛发展,数据科学领域正经历一场静默的革命。传统的特征工程、模型训练与迭代优化流程,正被智能化的研发助手所改变。

人工智能数据中心对电力的需求正迅速逼近电网承载极限,这已非新发现。

最近,北京大学陈宝权教授带领团队在三维形状生成和三维数据对齐方面取得新的突破。在三维数据生成方面,团队提出了3D自回归模型新范式,有望打破3D扩散模型在三维生成方面的垄断地位。

“让AI帮忙推荐楼盘,它说得有理有据,连户型都帮我选好了,我都心动了,结果它推荐的楼盘根本不存在……”然而,大家对AI的信任有时也会悄悄动摇:文中附上的引用链接变成失效的乱码,严谨的学术术语下包裹着虚构的参考文献,回答内容中的统计数据从未在标注信源中出现……
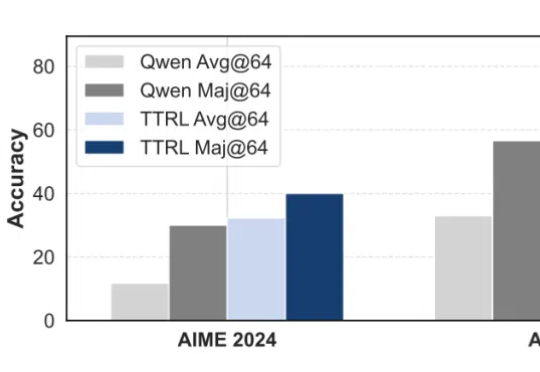
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!
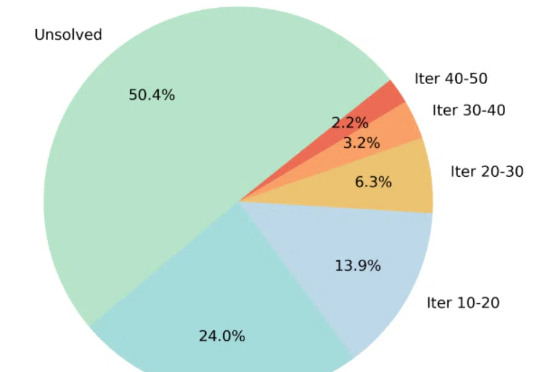
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。