
AI互动内容的怪异二三事
AI互动内容的怪异二三事就在Loopit新融资交割前的一个早晨,许多VC、大厂战投的合伙人们相继收到了一份数据报告。
来自主题: AI资讯
7981 点击 2026-06-11 09:55
 搜索
搜索
就在Loopit新融资交割前的一个早晨,许多VC、大厂战投的合伙人们相继收到了一份数据报告。
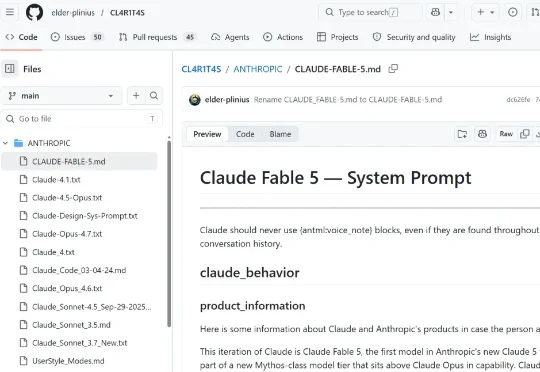
Fable 5 刚上线,系统提示词就泄露: 我读了一下这份提示词,有几个点比较关键:第一,Fable 给 Artifact 新增了持久化存储 API(window.storage)。Artifact 就是 Claude 用代码生成的独内容,比如 HTML 页面、React 组件等。以前 Artifact 不能保存数据,更像个一次性 demo。

顶级AI编码一日千里,到了生物学领域却频频翻车,并非模型不够聪明,而是科学数据库至今只为人类点鼠标而生。

具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。

英伟达买的是企业数据的理解力。

客户数量不是核心,能为客户解决的问题数量才是核心。

昨天,奇绩创坛举办了 2026 年春季创业营路演日,共有 56 个项目上台。从赛道分布来看,覆盖: 智能体(39 家)、具身与物理智能(19 家)、数据(10 家)、AI 基础设施(14 家)、FDE & AI 咨询(10 家)。

大模型还在混战,AI及智能硬件市场先跑出了三个“爆款”:AI眼镜、AI录音笔、3D打印机。
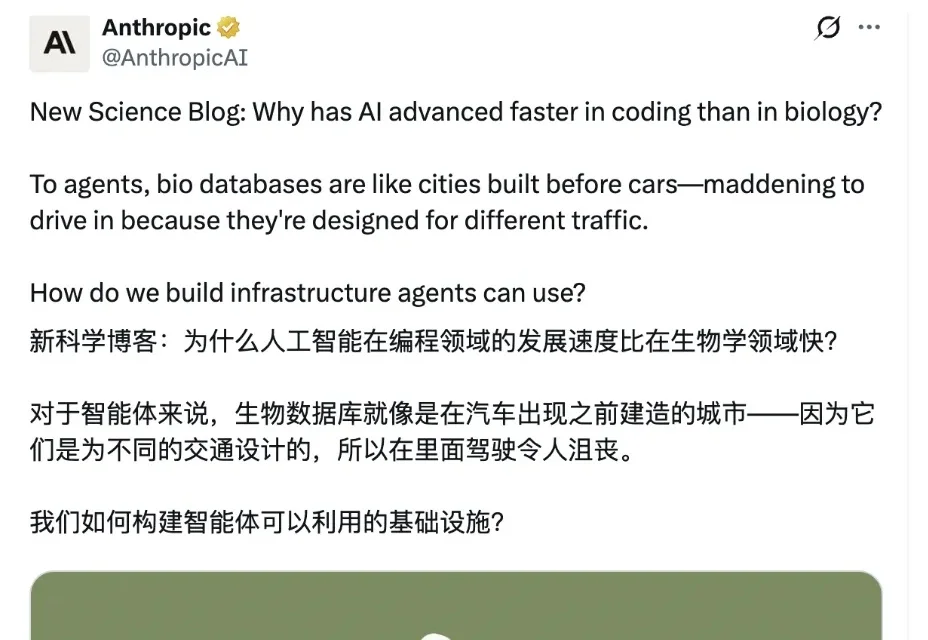
当前,Coding Agents 在软件工程领域一路高歌猛进,科学家们看到此场景,也不禁寄予厚望:AI 智能体何时能以同样的速度,帮人类攻克药物设计、病毒监控与生物学建模的重重难关?

“你将有机会参与从MW(兆瓦)到GW(吉瓦)级基础设施的规划与建设。”