
抢电、圈地、对赌,深聊科技巨头的千亿美元AI能源大战
抢电、圈地、对赌,深聊科技巨头的千亿美元AI能源大战各大巨头因AI军备竞赛,纷纷抢建数据中心,从抢芯片变成了抢能源。千亿美元投资背后,释放着怎样的信号?
来自主题: AI资讯
12114 点击 2024-05-15 17:41
 搜索
搜索
各大巨头因AI军备竞赛,纷纷抢建数据中心,从抢芯片变成了抢能源。千亿美元投资背后,释放着怎样的信号?

在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。

本文是对发表于模式识别领域顶刊Pattern Recognition 2024的最新综述论文:「Advancements in Point Cloud Data Augmentation for Deep Learning: A Survey 」的解读。

去年 11 月 8 日,新加坡政府科技局(GovTech)组织举办了首届 GPT-4 提示工程(Prompt Engineering)竞赛。数据科学家 Sheila Teo 最终夺冠,成为最终的提示女王(Prompt Queen)。

又是一年招聘季,就业市场的新主力正来势汹汹。数据显示,2024届高校毕业生规模预计1179万人,同比增加21万人。面临如此大规模的求职者,各大公司在招聘过程中正越来越多地使用AI工具。其中,AI面试已成为包括银行、外企和快消等领域的标配。

有数据统计,2022年全年,全国数据中心耗电量达到2700亿千瓦时,占全社会用电量约3%。预计2024年全国数据中心的耗电量将在3400亿至3600亿度之间,到2025年可能增长至4000亿至4400亿度。

凭借“黏土风滤镜”,借助“五一”期间用户发布旅游照片的热潮,Remini在国内的下载量暴增。据七麦数据,Remini自4月29日后下载量暴增,5月1日下载量增长至28.53万次,5月2日至5月8日一周内,下载量预估总计191.13万次
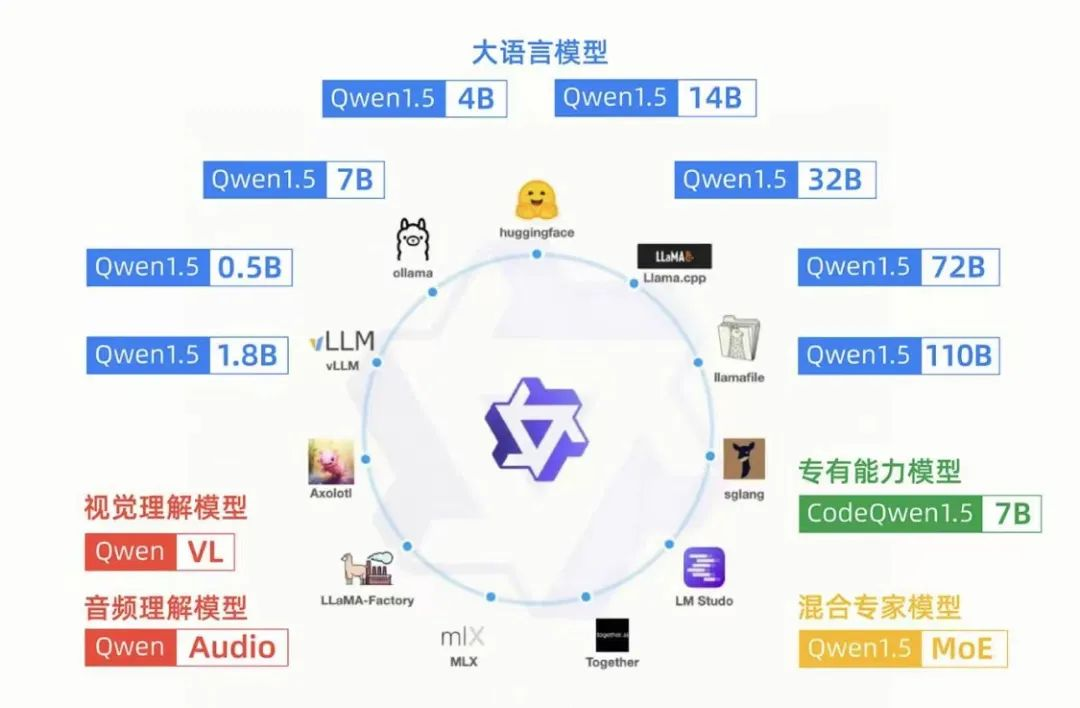
今年开年以来,大模型落地越来越火热。云计算大厂有关AI业务的数据在不断刷新。就在这样的时间节点上,5月9日,阿里云在北京举办AI峰会,除了发布阶段性的进展之外,还重点向与会者介绍了阿里云的大模型生态和落地平台,为大模型落地竞争再添一把火。
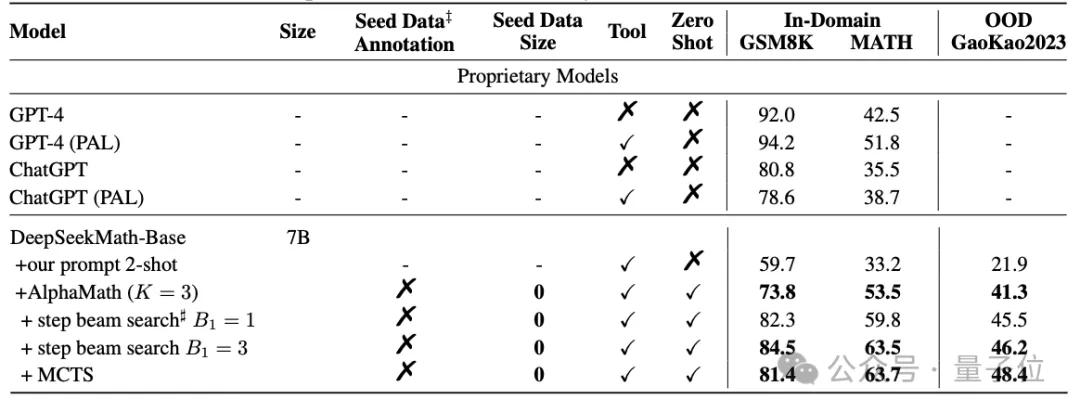
把AlphaGo的核心算法用在大模型上,“高考”成绩直接提升了20多分。
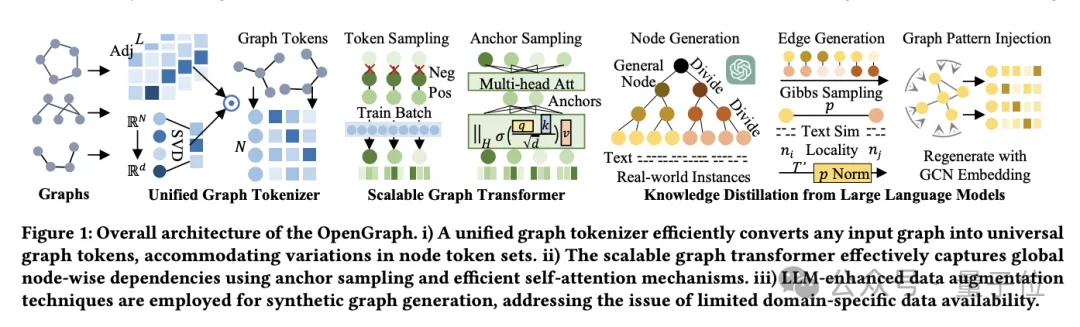
图学习领域的数据饥荒问题,又有能缓解的新花活了!