
苹果被曝自研数据中心AI芯片,内部代号“ACDC”
苹果被曝自研数据中心AI芯片,内部代号“ACDC”据《华尔街日报》7日报道,苹果公司正在为数据中心服务器研发设计运行人工智能(AI)软件的芯片,这一举措或将使苹果在日益激烈的AI领域军备竞赛中占据优势。
来自主题: AI技术研报
9546 点击 2024-05-08 19:05
 搜索
搜索
据《华尔街日报》7日报道,苹果公司正在为数据中心服务器研发设计运行人工智能(AI)软件的芯片,这一举措或将使苹果在日益激烈的AI领域军备竞赛中占据优势。

多模态融合是多模态智能中的基础任务之一。

今年 3 月,以构建大型开源社区而闻名的 AI 初创公司 Hugging Face,挖角前特斯拉科学家 Remi Cadene 来领导一个新的开源机器人项目 ——LeRobot,引起了轰动。

根据路透社5月4日消息,著名华人计算机科学家李飞飞正在建立一家初创公司。这家公司会利用类似人类对视觉数据的处理,使 AI 能够进行高级推理。这种AI算法使用的概念被称为“空间智能”。至于新公司的名字,还没有向外界披露。

过去几年,借助Scaling Laws的魔力,预训练的数据集不断增大,使得大模型的参数量也可以越做越大,从五年前的数十亿参数已经成长到今天的万亿级,在各个自然语言处理任务上的性能也越来越好。

过去一年,AI大模型无疑是科技行业中最亮眼的主角,从FAAMG到BAT、再到一众初创企业,无数优秀的大脑、海量的资源都投入到了这个有望解放人类生产力的赛道中。

Meta最近开源的Llama 3模型再次证明了「数据」是提升性能的关键,但现状是,开源的大模型有一堆,可开源的大规模数据却没多少,而收集、清洗数据又是一项极其费时费力的工作,也导致了大模型预训练技术仍然掌握在少数高端机构的手中。

近年来,大型语言模型(LLM)在数学应用题和数学定理证明等任务中取得了长足的进步。数学推理需要严格的、形式化的多步推理过程,因此是 LLMs 推理能力进步的关键里程碑, 但仍然面临着重要的挑战。

使用测序 (scATAC-seq) 技术对转座酶可及的染色质进行单细胞测定,可在单细胞分辨率下深入了解基因调控和表观遗传异质性,但由于数据的高维性和极度稀疏性,scATAC-seq 的细胞注释仍然具有挑战性。现有的细胞注释方法大多集中在细胞峰矩阵上,而没有充分利用底层的基因组序列。
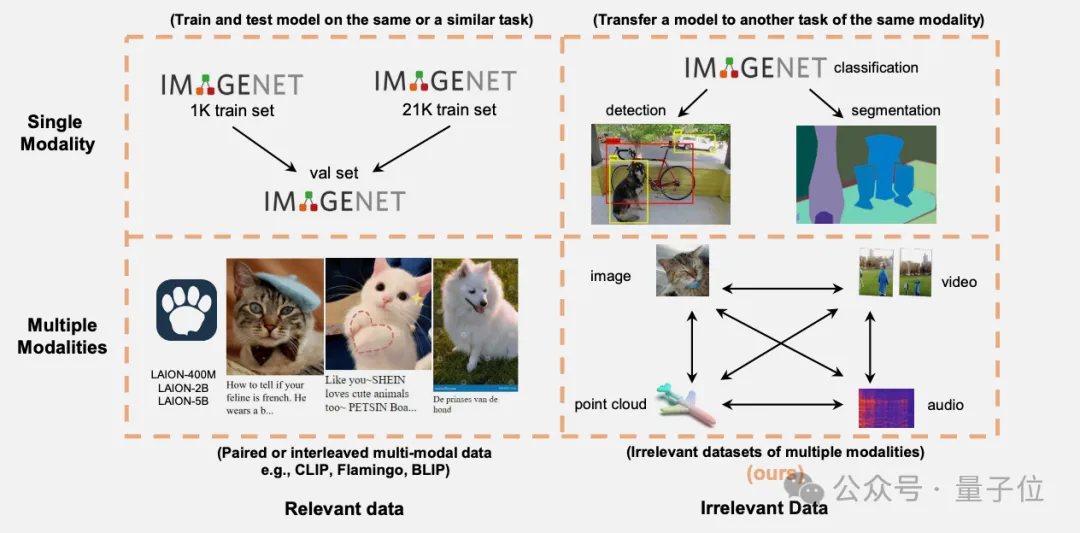
万万没想到,与任务无直接关联的多模态数据也能提升Transformer模型性能。