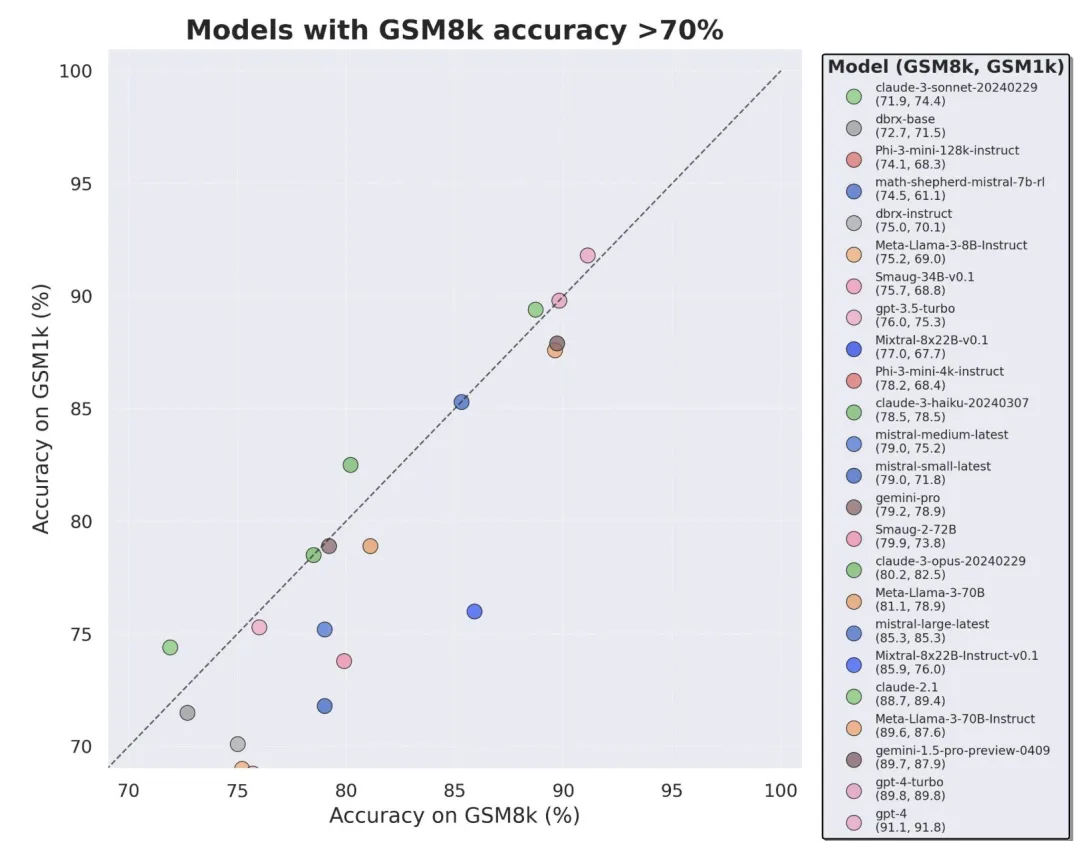
终于有人调查了小模型过拟合:三分之二都有数据污染,微软Phi-3、Mixtral 8x22B被点名
终于有人调查了小模型过拟合:三分之二都有数据污染,微软Phi-3、Mixtral 8x22B被点名当前最火的大模型,竟然三分之二都存在过拟合问题?
来自主题: AI技术研报
6927 点击 2024-05-03 20:54
 搜索
搜索
当前最火的大模型,竟然三分之二都存在过拟合问题?

自2021年诞生,CLIP已在计算机视觉识别系统和生成模型上得到了广泛的应用和巨大的成功。我们相信CLIP的创新和成功来自其高质量数据(WIT400M),而非模型或者损失函数本身。虽然3年来CLIP有大量的后续研究,但并未有研究通过对CLIP进行严格的消融实验来了解数据、模型和训练的关系。
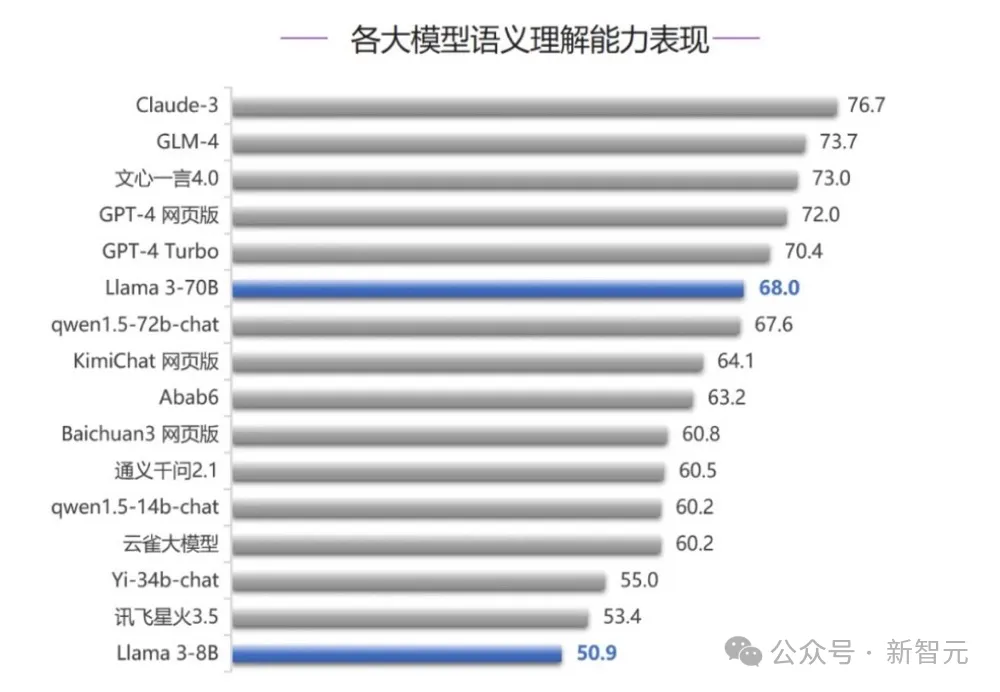
就在最近,清华大学SuperBench团队的新一轮全球大模型评测结果出炉了!
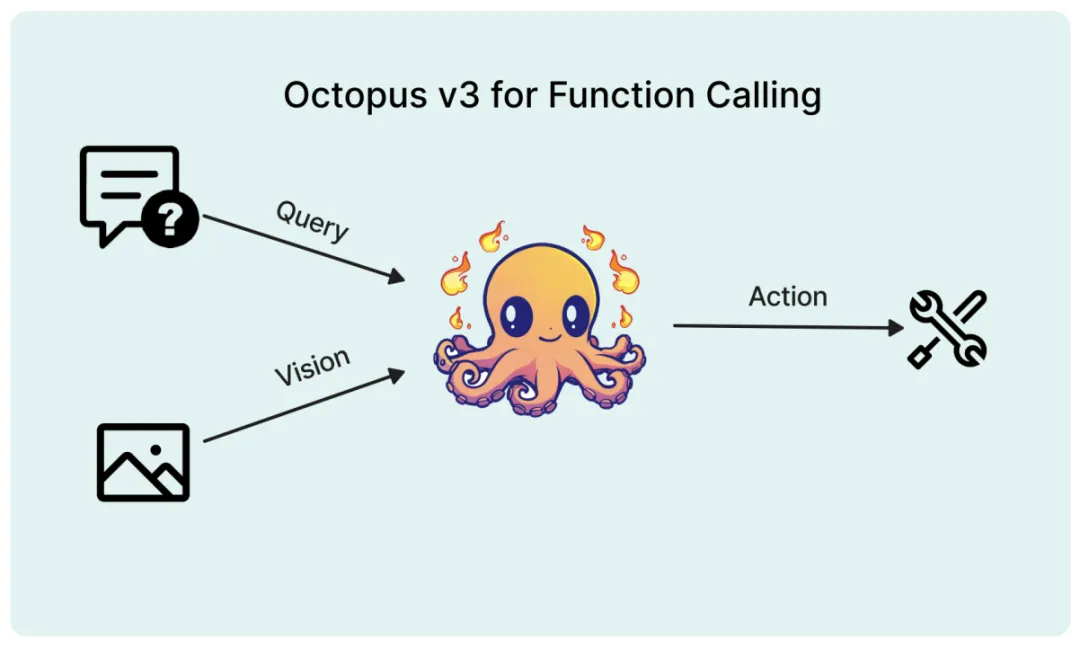
多模态 AI 系统的特点在于能够处理和学习包括自然语言、视觉、音频等各种类型的数据,从而指导其行为决策。近期,将视觉数据纳入大型语言模型 (如 GPT-4V) 的研究取得了重要进展,但如何有效地将图像信息转化为 AI 系统的可执行动作仍面临挑战。

近日,上海交通大学自然科学研究院/物理与天文学院/张江高等研究院洪亮课题组,在生物信息学和人工智能研究领域的国际权威学术期刊JCIM(Journal of Chemical Information and Modeling)上发表最新研究成果
训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。
大模型力大砖飞,让LLaMA3演绎出了新高度: 超15T Token数据上的超大规模预训练,既实现了令人印象深刻的性能提升,也因远超Chinchilla推荐量再次引爆开源社区讨论。

大模型语料是指用于训练和评估大模型的一系列文本、语音或其他模态的数据。
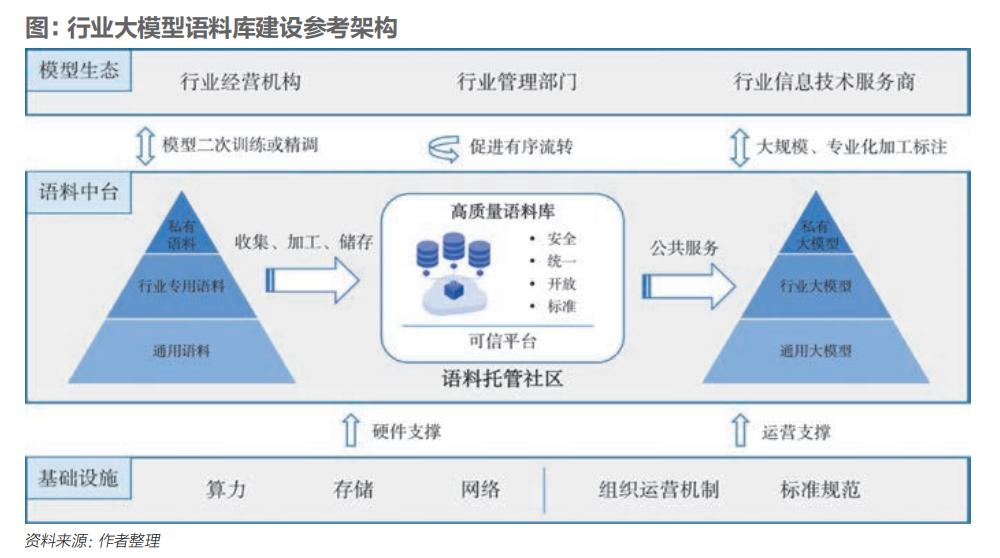
大模型语料是指用于训练和评估大模型的一系列文本、语音或其他模态的数据。语料规模和质量对大模型性能以及应用的深度、广度有着至关重要的影响。

要说 ChatGPT 拉开了大模型竞赛的序幕,那么 Meta 开源 Llama 系列模型则掀起了开源领域的热潮。在这当中,苹果似乎掀起的水花不是很大。