
无需标注图像,VLM也能「自我进化」!RL自我进化框架VisPlay突破视觉推理难题
无需标注图像,VLM也能「自我进化」!RL自我进化框架VisPlay突破视觉推理难题在 Vision-Language Model 领域,提升其复杂推理能力通常依赖于耗费巨大的人工标注数据或启发式奖励。这不仅成本高昂,且难以规模化。
来自主题: AI技术研报
9712 点击 2025-12-02 15:22
 搜索
搜索
在 Vision-Language Model 领域,提升其复杂推理能力通常依赖于耗费巨大的人工标注数据或启发式奖励。这不仅成本高昂,且难以规模化。

今天,The Information从投资者文件和知情人士处获悉,AI数据分析平台Databricks正在洽谈一轮规模高达50亿美元(约合人民币354亿元)的新融资,此轮融资中,Databricks的估值已经飙升至1340亿美元(约合人民币9481亿元)。

5000亿美元,是NASA预估能让人类完成火星登陆的预算、能买下1.36个阿里(3670亿美元)、3.5个NBA联盟(1400亿美元)、建设100座Apple Park(50亿美元)、买1400亿杯咖啡(3.5美元),却只够OpenAI建一座Stargate数据中心。

Perplexity 的首席执行官 Aravind Srinivas 曾直言不讳:“世上万物皆是套壳(Everything is a wrapper)。OpenAI 套的是英伟达的算力和 Azure 的云服务;Netflix 套的是 AWS 的基础设施;就连市值高达 3200 亿美元的 Salesforce,归根结底也不过是 Oracle 数据库的一个高级外壳。”你

对于谷歌(Google)而言,刚刚过去的一周可以看作其人工智能战略转型的关键节点。随着 Gemini 3 的正式发布,以及名为 Nano Banana Pro 的新模型在社交媒体与开发者社区中迅速走红,这家科技公司正在重新找回自己在 AI 领域的节奏与底气。
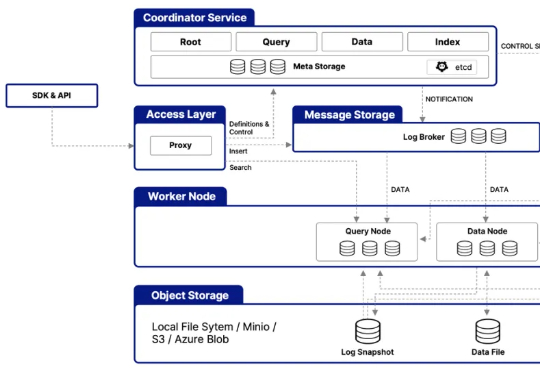
在架构层面,Milvus 2.6 大幅简化系统架构,整合多个核心组件 —— 例如将原有的 Coordinator 组件(含 RootCoord、QueryCoord、DataCoord)统一整合为 MixCoord,并将 IndexNode 与 DataNode 合并为单一组件。这些调整不仅降低了系统复杂度,更显著提升了系统的可维护性与横向扩展性。
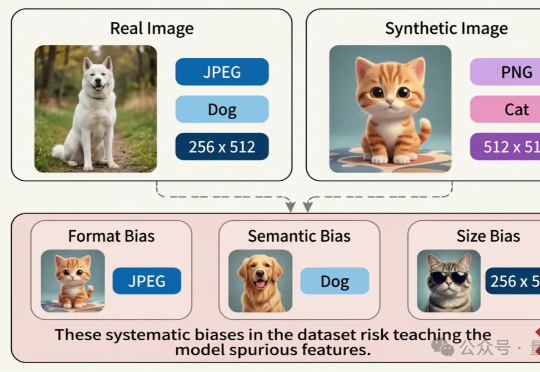
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。

Digital Connexion 是由穆克什·安巴尼的依赖工业有限公司 、布鲁克菲尔德资产管理公司以及 Digital Realty Trust 共同组建的合资企业,已签署协议计划到 2030 年投资 110 亿美元在印度南部开发 数据 中心设施,标志着对科技领域增长最快赛道之一的最新投资。
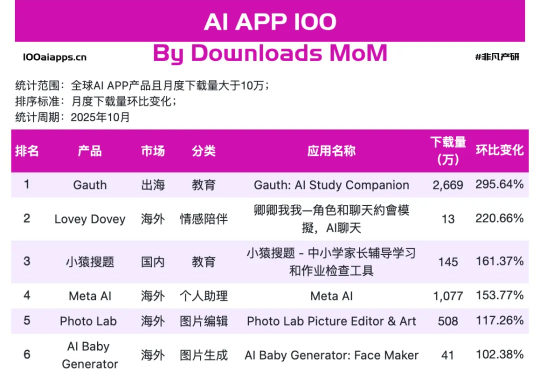
但当我们把视线从焦点模型上,挪到手机里AI应用真实数据上,就会发现一幅不同的画面。可以看到在非凡产研 10 月 AI App 增速榜上,跑得最快的那 17 个,并不是万事皆可聊的通用助手,而是一群看上去有点普通、甚至有点土气的小应用,其中Gauth、Starry、Knowunity、AI Baby Generator已经连续两个月上榜了。

Veza 的订阅软件帮助企业了解其员工以及自动化软件任务的 AI Agent对特定客户或公司数据的访问权限,以及他们能对这些数据做什么。ServiceNow 一直在加强其 AI Agent相关的产品,这些产品旨在自动化客户服务和响应IT 帮助台请求等任务。