
字节/腾讯、大疆背景构成的核心团队做AI滑雪穿戴硬件,Heygo.ai 已完成两轮千万级融资
字节/腾讯、大疆背景构成的核心团队做AI滑雪穿戴硬件,Heygo.ai 已完成两轮千万级融资Heygo.ai对比每一次滑行数据,分析动作变化,并明确告诉接下来需要改进的地方。基于你的专属数据、滑行风格、习惯,为有经验的爱好者制定一套系统化的训练方案,精准攻克薄弱环节。
来自主题: AI资讯
7664 点击 2026-05-31 14:33
 搜索
搜索
Heygo.ai对比每一次滑行数据,分析动作变化,并明确告诉接下来需要改进的地方。基于你的专属数据、滑行风格、习惯,为有经验的爱好者制定一套系统化的训练方案,精准攻克薄弱环节。

大模型从“回答问题”走向“完成任务”,正在面临以下瓶颈:面向Claw Agents的数据、训练和评测都比传统environment training更难。为了解决该问题,中国人民大学、至知研究院等最新提出ClawGym——

2026年5月,两篇重磅研究在一周内相继发表。一组来自加州大学伯克利分校研究团队,样本是美国 20 所公立研究型大学的 95,513 名本科生。研究发表在《Science》科学杂志上,主题是大学生如何使用生成式 AI,以及怎样用它作弊。

就在前两天,斯坦福大学等机构发布了一个名为 GPIC(Giant Permissive Image Corpus,巨型开放图像语料库)的数据集。
普通人看排行榜估计越看越疑惑,写文章该用哪个?数据分析该用哪个?写代码、审 PR、拆任务又该用哪个?我挑了四款最近讨论度很高的模型:Claude Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,做一次横评,看看它们在真实任务里的交付表现。

绝大多数 AI 陪伴产品,都是基于通用模型的使用,利用提示词框架对模型进行定向约束,所以角色的表达仍然停留在「人类平均水平」,本质都是提示词驱动下的角色扮演。但陆弘毅做蕾伊的方法完全不同。团队先为她写了几十万字的人格语料,确定她从小到大的经历、行为与反应、深层性格和内在冲突,再把这些只属于蕾伊的数据灌进他们自研的「超人格化模型」。

昨天,大名鼎鼎的 Claude 4.8 发布了。 科技圈照例是一片欢呼。 看官方放出来的一堆评测数据,依然是碾压级别的,尤其是说代码(Coding)能力有了史诗级的提升,简直像交了一份满分答卷。
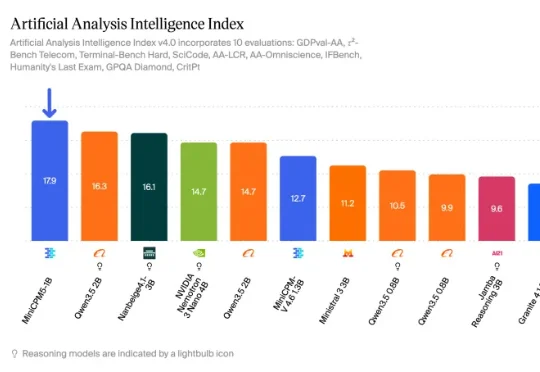
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。一共是两份 L3 级数据集:Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。

Omdia这份名为《2026全球AI工厂市场格局》的报告,点明了新时代的核心逻辑——决定胜负的,不再是谁拥有更多GPU,而是谁能够更高效地把“电力+算力+数据”转化为真正有价值的Token。

Google DeepMind研究院姚顺宇最近接受媒体人采访时说:做一个好的产品经理,是一个我现在想不明白该怎么训练AI去做的事。言外之意,AI时代产品经理很难被替代。招聘市场已经给出了答案。根据脉脉2026年1—4月的数据,热招岗位里大模型算法排第一,产品经理排第二,AI产品经理也排到了前五的位置。