
万字深度|做了8年向量数据库后,我们决定为Milvus重构AI时代的存储引擎
万字深度|做了8年向量数据库后,我们决定为Milvus重构AI时代的存储引擎过去八九年,我们一直在做一件事:把向量数据库从一个很小众的系统方向,做成 AI 基础设施里的关键组件。
来自主题: AI技术研报
7669 点击 2026-06-03 14:31
 搜索
搜索
过去八九年,我们一直在做一件事:把向量数据库从一个很小众的系统方向,做成 AI 基础设施里的关键组件。

Liquid AI 近期推出的 LocalCowork,正是直面这一矛盾的产物:单台笔记本,无需云端 API,数据绝不离机。凭借 67 个本地工具、13 个 MCP Servers,配合最新发布的 LFM2.5-8B-A1B 模型,它通过本地调用工具、解释结果以及可审计的工作流,解决了上述难题。

近日,「智能知识」(Human Intelligence)完成天使轮融资,由耀途资本、锦秋基金联合投资。本轮融资资金将用于两个方向:前沿数据品类扩张:深耕 Coding、Enterprise Office(GDPVal)、Agentic Tool Use 等高价值数据,并积极探索 AI4Math、AI4Science、AutoResearch 等新场景;

软银集团计划在法国投资高达 750 亿欧元(约合 870 亿美元),建设 5 吉瓦的人工智能数据中心容量,称该国有望成为欧洲顶级 AI 基础设施枢纽。软银周六在一份声明中表示,第一阶段将投入 450 亿欧元,到 2031 年在法国上法兰西大区交付 3.1 吉瓦的 AI 数据中心容量。
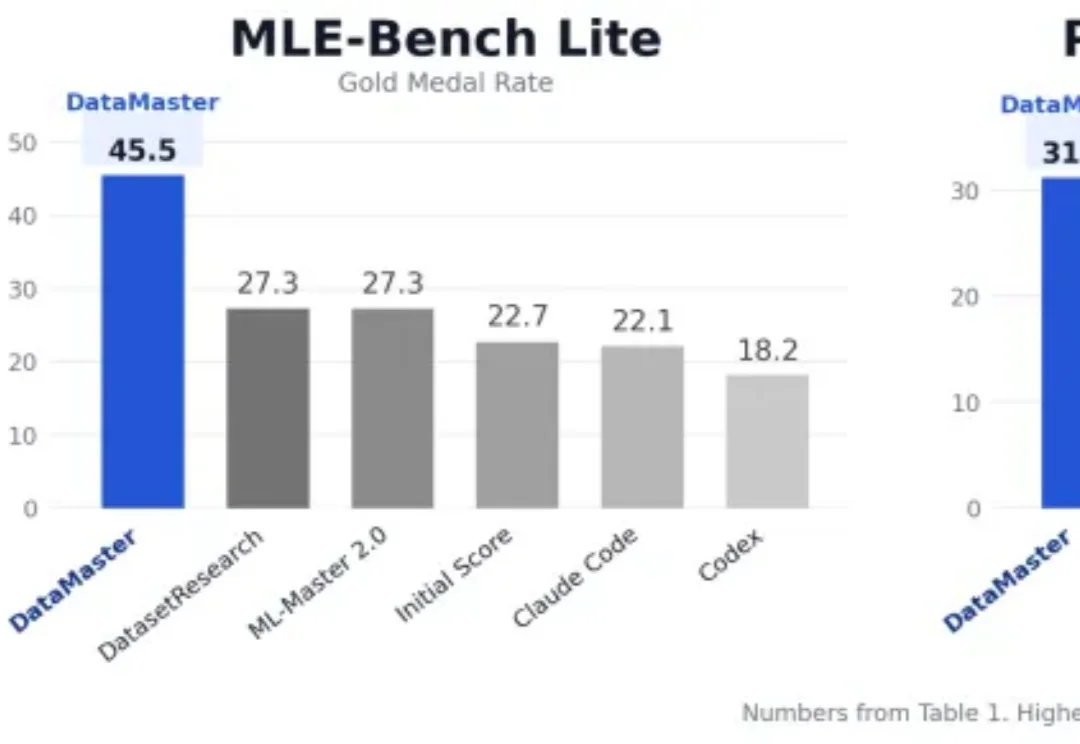
过去,AI 研发基本是一条由人主导的流水线。

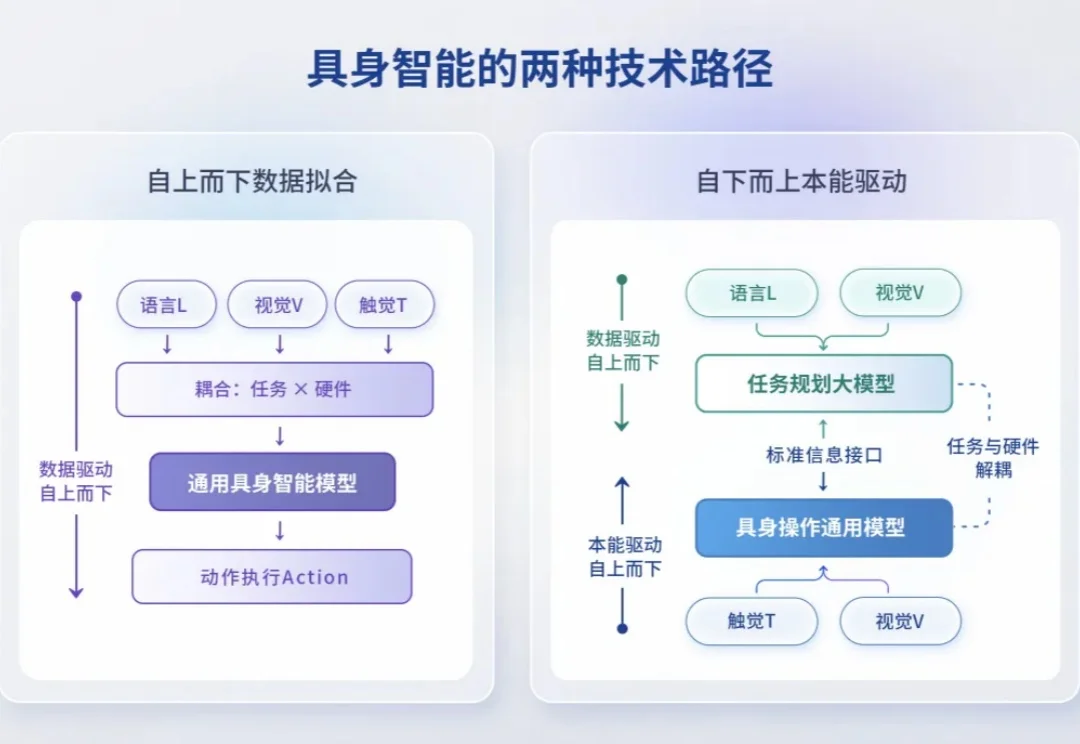
2018 年从哈佛回国时,橡木果机器人的发起人姜峣有了一个判断:语言和操作,是两种完全不同的智能。
这是第一次,机器人学会了用手「盘」:
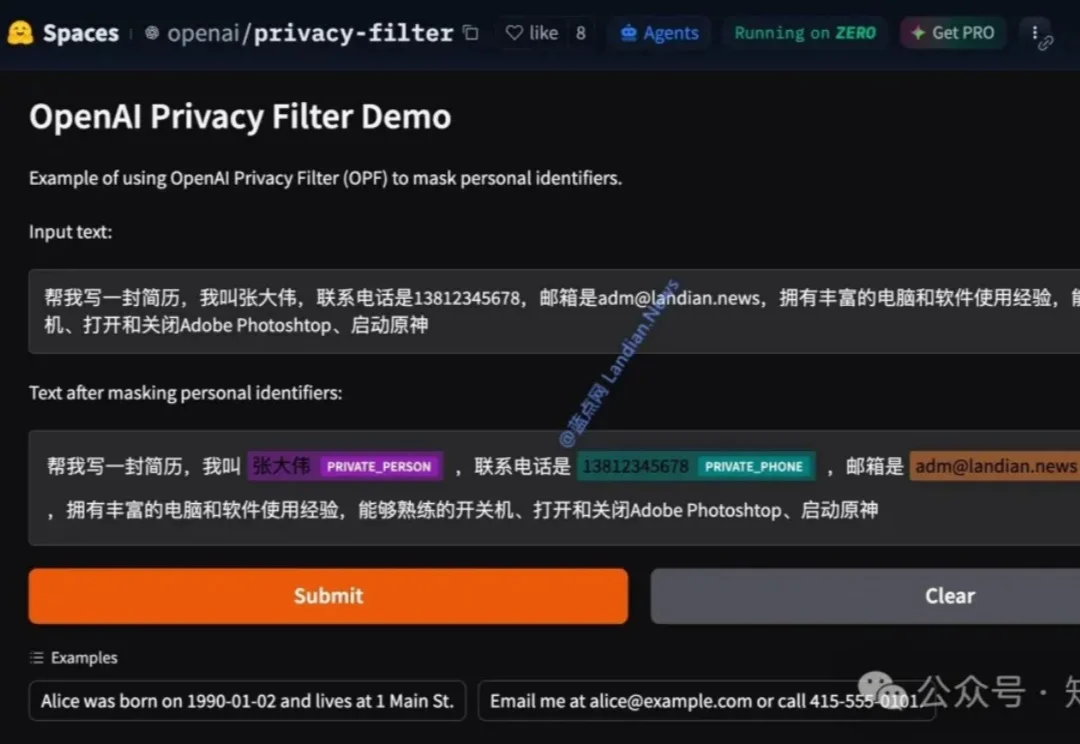
你有没有过这样的经历:把聊天记录、用户反馈或内部文档丢给大模型时,总担心里面夹杂着真实姓名、手机号、邮箱甚至 API key,最后只能手动一条条删?或者团队在处理海量数据时,规则写的正则永远漏掉那些“藏在句子里的隐私”。
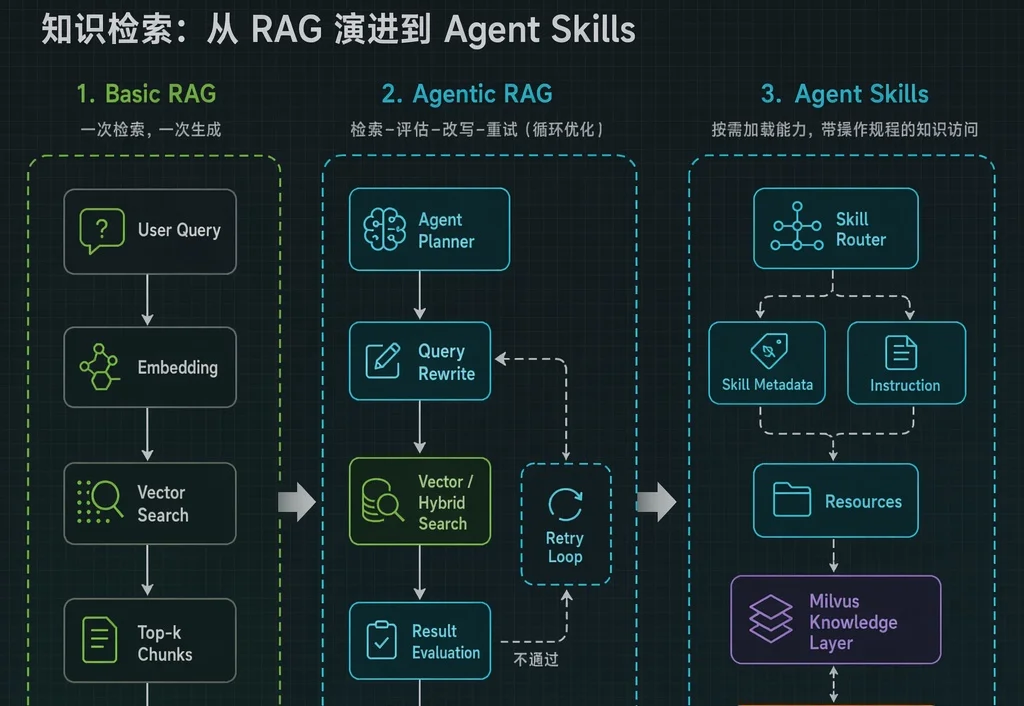
最近一两年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。
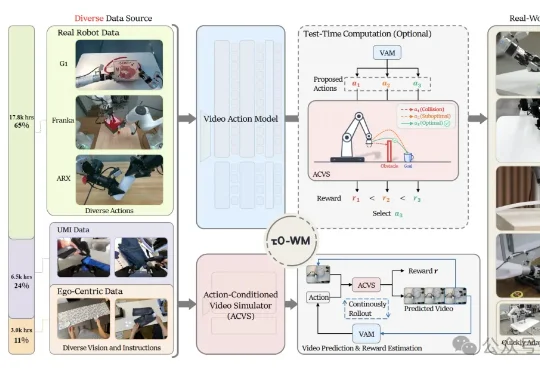
刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。