
独家丨星海图将发布首个开放世界真机数据集及VLA开源模型
独家丨星海图将发布首个开放世界真机数据集及VLA开源模型硅星人独家了解到,星海图即将开源全球首个开放场景高质量真机数据集Galaxea Open-World Dataset,及其G0-快慢双系统全身智能VLA模型。这一举动无疑在相对各自为战的机器人行业打开了一条新的路径。
来自主题: AI资讯
11035 点击 2025-08-11 14:05
 搜索
搜索
硅星人独家了解到,星海图即将开源全球首个开放场景高质量真机数据集Galaxea Open-World Dataset,及其G0-快慢双系统全身智能VLA模型。这一举动无疑在相对各自为战的机器人行业打开了一条新的路径。

扩散语言模型(DLMs)是超强的数据学习者。 token 危机终于要不存在了吗? 近日,新加坡国立大学 AI 研究者 Jinjie Ni 及其团队向着解决 token 危机迈出了关键一步。
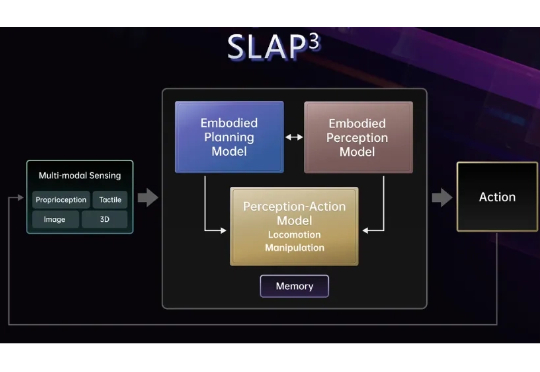
7 月 27 日,腾讯发布了具身智能开放平台 Tairos,以模块化的方式向行业提供大模型、开发工具和数据服务,试图为具身智能的研发和应用提供一套通用的支撑体系。

从实验观察,到理论构建,再到计算仿真,科学的进步始终伴随着范式的更迭。而今,AI正作为核心引擎,驱动着以数据为中心的“第四范式”破土而出,一个前所未有的科学大发现时代正由此展开。
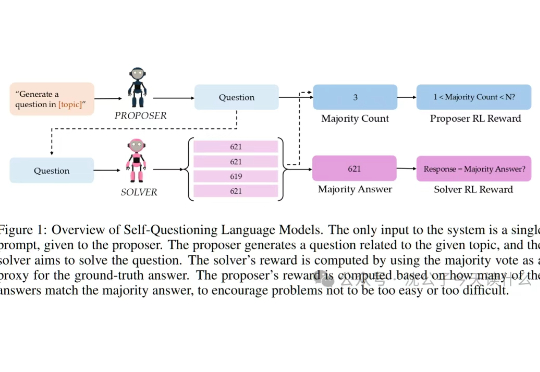
一句话概括,本文探索了语言模型的终极内卷模式:不再依赖人类投喂,通过“自问自答”的左右互搏,硬生生把自己逼成了学霸。AlphaGo下棋我懂,这大模型自己给自己出数学题做就有点离谱了,堪称AI界的“闭关修炼”,出关即无敌。

日前有网友发现沉浸式翻译扩展程序的部分用户数据暴露在互联网上,这些数据包含部分敏感内容例如加密货币钱包私钥甚至是企业 / 机构的商业合同等。严格来说此次问题并非安全漏洞而是沉浸式翻译提供的功能存在缺陷,即没有对快照链接进行保护导致搜索引擎爬虫可以直接抓取内容并将其放置互联网上公开索引。
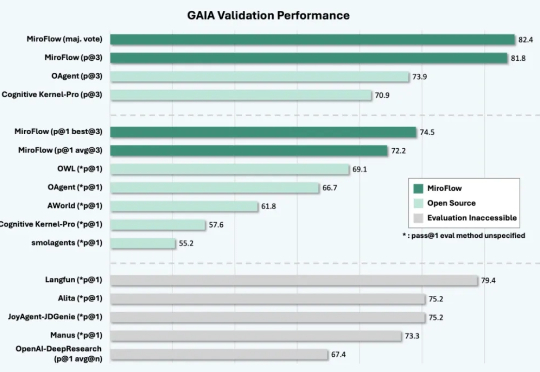
全栈开源生态系统:涵盖Agent框架(MiroFlow)、模型(MiroThinker)、数据(MiroVerse)和训练基础设施(MiroTrain / MiroRL)的全栈开源方案,所有组件和流程均开放共享,便于学习、复用与二次开发。

近年来,AI社交赛道作为一个快速崛起的“品种”,曾凭借玩法新颖与技术想象力迅速吸引了市场关注。然而,随着入局者增加,赛道逐渐暴露出增长瓶颈:玩法趋于固化、功能高度同质化、用户体验缺乏持续吸引力。种种迹象都在指向一个信号:市场正在走向降温与饱和。
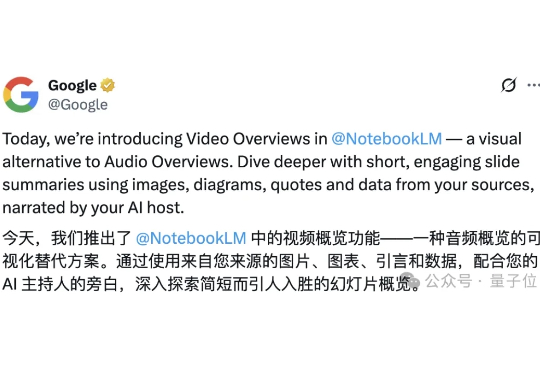
打工人超超超实用利器来了!还在自己苦巴巴地做汇报,干巴巴地念PPT么? 谷歌NotebookLM最新功能,只需要输入数据、图表、旁白,就可以自动生成带AI音频的PPT,甚至不需要自己去讲。
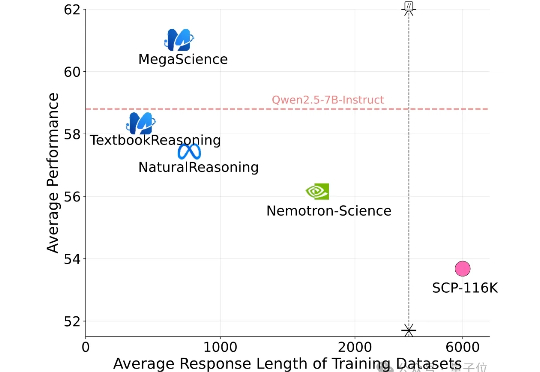
有史规模最大的开源科学推理后训练数据集来了! 上海创智学院、上海交通大学(GAIR Lab)发布MegaScience。该数据集包含约125万条问答对及其参考答案,广泛覆盖生物学、化学、计算机科学、经济学、数学、医学、物理学等多个学科领域,旨在为通用人工智能系统的科学推理能力训练与评估提供坚实的数据。