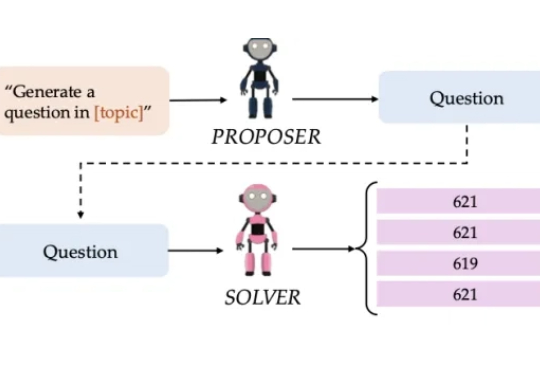
无需外部数据!AI自问自答实现推理能力进化
无需外部数据!AI自问自答实现推理能力进化AI通过自问自答就能提升推理能力?! 这正是卡内基梅隆大学团队提出的新框架SQLM——一种无需外部数据的自我提问模型。
来自主题: AI资讯
7317 点击 2025-08-08 16:56
 搜索
搜索
AI通过自问自答就能提升推理能力?! 这正是卡内基梅隆大学团队提出的新框架SQLM——一种无需外部数据的自我提问模型。

心理健康问题影响着全球数亿人的生活,然而患者往往面临着双重负担:不仅要承受疾病本身的痛苦,还要忍受来自社会的偏见和歧视。世界卫生组织数据显示,全球有相当比例的心理健康患者因为恐惧社会歧视而延迟或拒绝治疗。
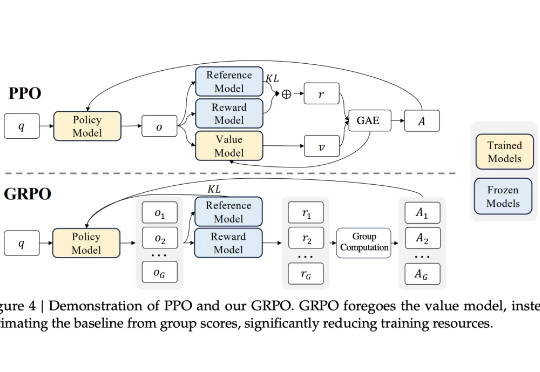
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。

QuestMobile 发布了 2025 年国内 AI 应用的上半年报告,总的来说,相比海外市场 app 和 web 市场都很火热的情况,国内市场的情况差别比较大。

AI行业对数据的渴求程度,质量大于数量。
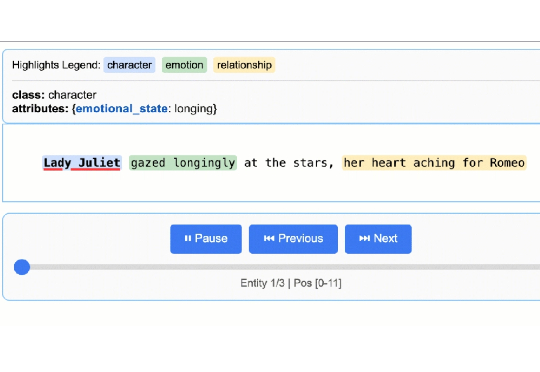
LangExtract 是一个 Python 库,利用大型语言模型(LLMs)从非结构化文本中提取结构化信息,基于用户定义的指令。它可以处理临床笔记或报告等材料,识别并组织关键细节,同时确保提取的数据与源文本对应。
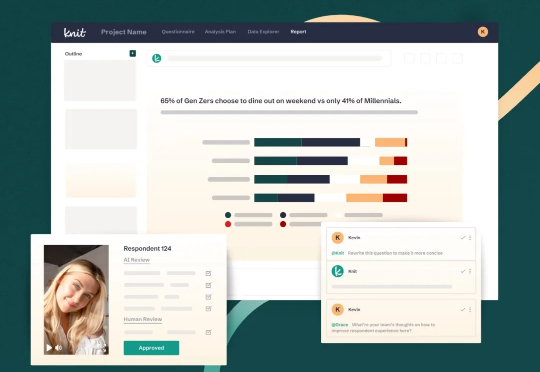
当传统调研机构还在用老套路——焦点小组、电话访谈、数周的数据分析——来服务客户时,一家名为 Knit 的创业公司正在用完全不同的方式重新定义这个价值数百亿美元的行业。他们刚刚完成了 1610 万美元的 A 轮融资,由 GFT Ventures 和阿什顿·库彻的 Sound Ventures 领投,这不仅仅是一笔投资,更是对企业洞察未来方向的一次重大押注。
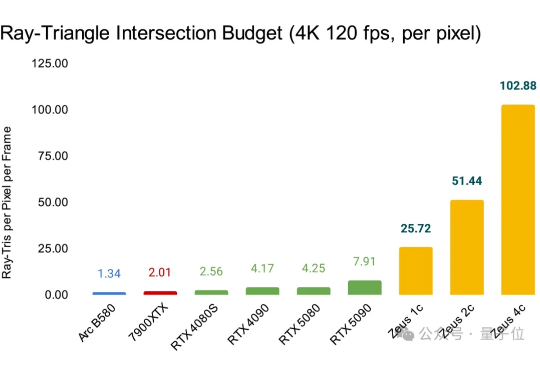
NVIDIA和AMD,终于有对手了? 一家名不见经传的芯片初创公司——Bolt Graphics,在最新发布的测试中抛出惊人数据: 其首款GPU模组Zeus 4C,在路径追踪(Path Tracing)场景中,性能飙至RTX 5090的13倍。
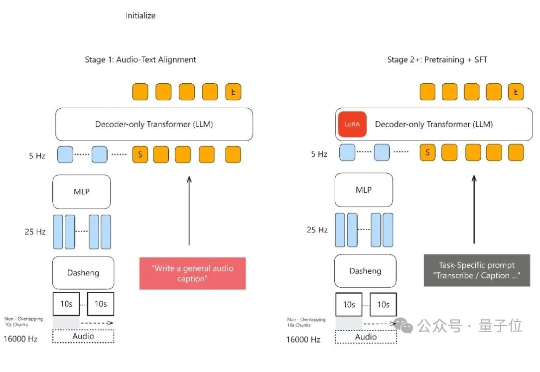
声音理解能力新SOTA,小米全量开源了模型。 MiDashengLM-7B,基于Xiaomi Dasheng作为音频编码器和Qwen2.5-Omni-7B Thinker作为自回归解码器,通过创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。
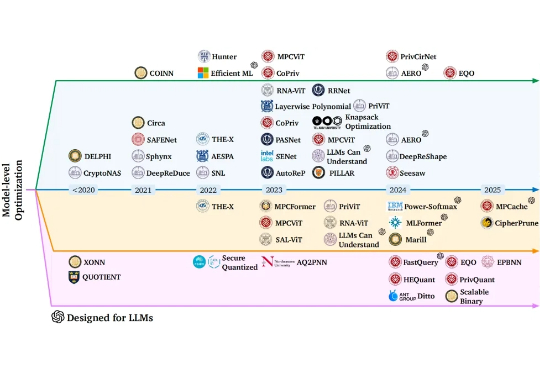
在数据隐私日益重要的 AI 时代,如何在保护用户数据的同时高效运行机器学习模型,成为了学术界和工业界共同关注的难题。