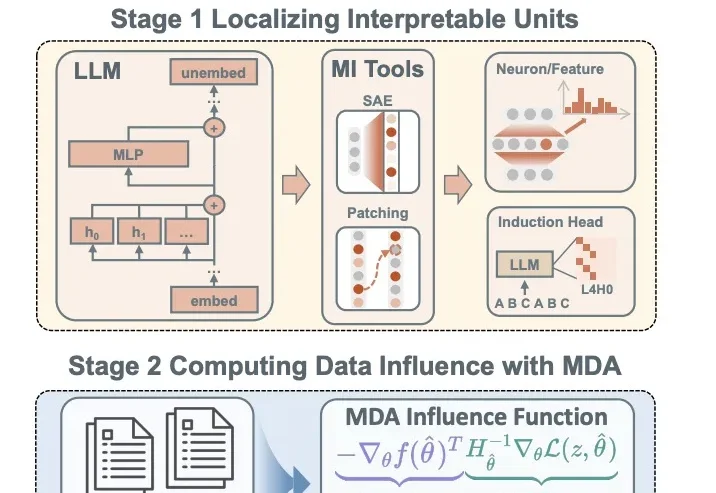
ICML 2026 Oral|大模型的能力从哪些训练数据来?北大&智源提出「机理数据归因」
ICML 2026 Oral|大模型的能力从哪些训练数据来?北大&智源提出「机理数据归因」近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。
来自主题: AI技术研报
9013 点击 2026-06-29 09:19
 搜索
搜索
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。

刚刚过去的2026智源大会上,由智源研究院孵化的星源智发布了全球首个具身交互世界模型ω-EVA,就这一前沿命题给出了全新的差异化解法。传统世界模型的困境是"只预测,不参与"。它们训练时学习未来状态,推理时却与动作生成分割——视频生成得再精美,机器人该撞墙还是撞墙。

6月的北京还处在初夏,胡同里的槐花已谢,蝉鸣未起。而中关村已把AI推向盛夏的热闹。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

由智源研究院牵头研发的众智 FlagOS 第一时间对两个“巨无霸”模型进行全量适配,已经完成 DeepSeek-V4-Flash 在8款以上 AI 芯片上的全量适配与推理部署,包括海光、沐曦、华为昇腾、摩尔线程(FP8)、昆仑芯、平头哥真武、天数、英伟达(FP8)等芯片。FlagOS 同时正在推进 DeepSeek-V4-Pro 模型在多个芯片的迁移适配,晚些时间开源出来,敬请期待。
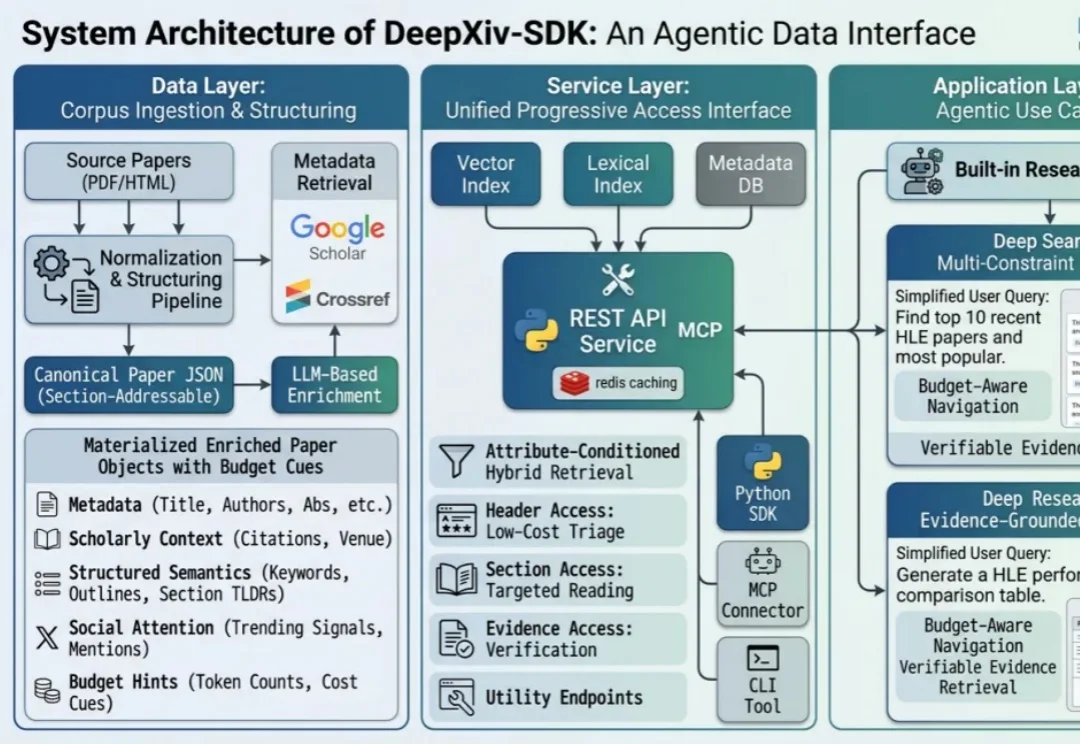
DeepXiv 是专为智能体设计的科技文献基础设施,把论文搜索、渐进式阅读、热点追踪和深度调研变成可调用、可编排、可自动化的能力。


昨天,具身智能的圈子“炸”了。不是因为某家公司发布了新产品,而是因为一场“具身武林大会”—— 2025智源具身智能Open Day。现场有多火爆?这么说吧,银河通用、智元、星海图、自变量、原力灵机、加速进化、北京人形、星源智、优必选、

智源研究院(BAAI)、Spin Matrix、乐聚机器人与新加坡南洋理工大学等联合提出了一个全新的终身记忆系统——RoboBrain-Memory。RoboBrain-Memory是全球范围内首个专为全双工、全模态模型设计的终身记忆系统,旨在解决具身智能体在真实世界的复杂交互问题,不仅支持实时音视频中多用户身份识别与关系理解,还能动态维护个体档案与社会关系图谱,从而实现类人的长期个性化交互。

最新最强的开源原生多模态世界模型—— 北京智源人工智能研究院(BAAI)的悟界·Emu3.5来炸场了。 图、文、视频任务一网打尽,不仅能画图改图,还能生成图文教程,视频任务更是增加了物理真实性。