
端侧跑大模型,现在也太简单了
端侧跑大模型,现在也太简单了最近,我们都在关注旗舰级大模型的进步,其实本地运行的 AI 模型也迎来了重要的分水岭。
来自主题: AI技术研报
8166 点击 2026-06-24 16:58
 搜索
搜索
最近,我们都在关注旗舰级大模型的进步,其实本地运行的 AI 模型也迎来了重要的分水岭。

今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。

小米UltraSpeed需求远超预期。
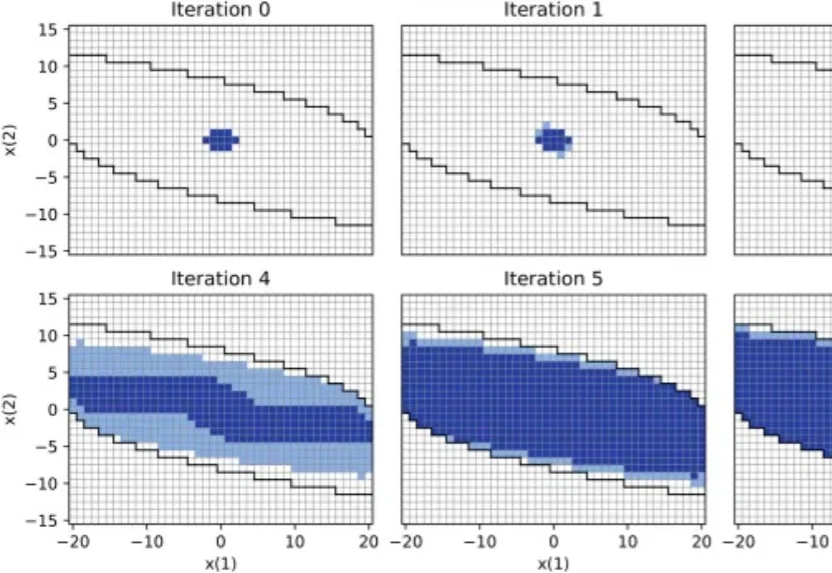
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。
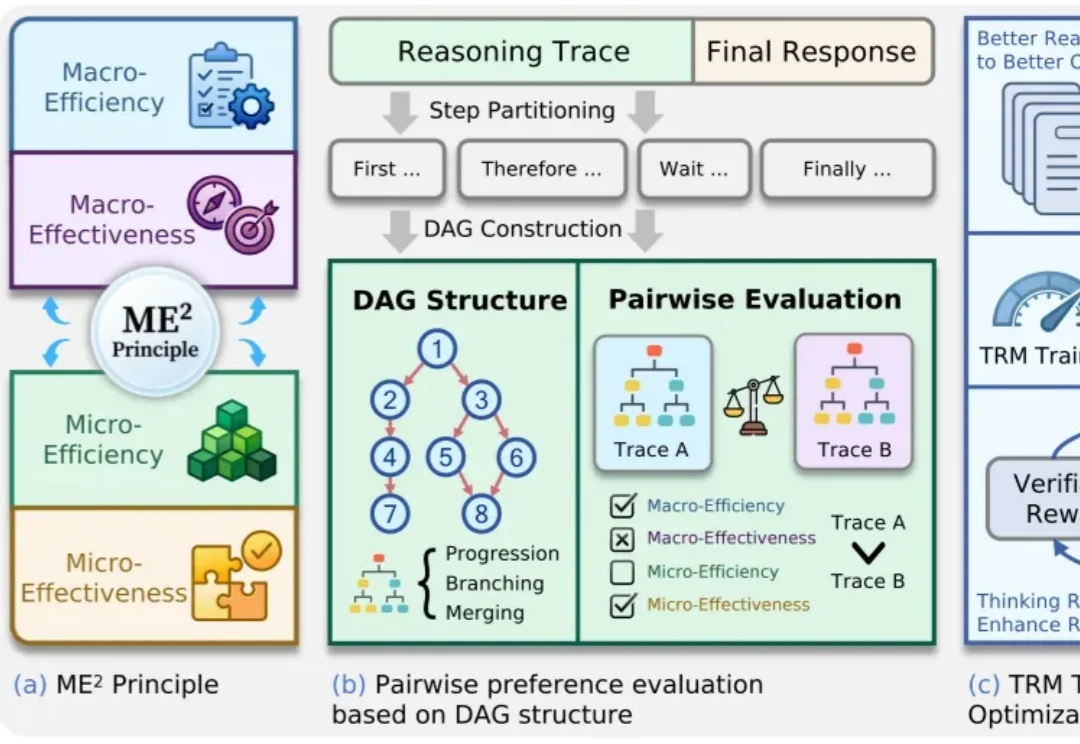
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?

当大模型公司还在竞争更长的上下文窗口、更强的推理能力和更复杂的 Agent 工作流时,一家名为 Engram 的新公司选择押注另一个问题:AI 能不能像人一样,持续从每天接触到的资料、对话和经验中学习?

今天,字节跳动旗下AI应用豆包正式推出专业版以及对应收费方案。豆包专业版基于最新的豆包2.1系列大模型,将提供更高的生产力场景使用额度,以及接入豆包2.1 Pro模型的全新“办公任务”模式。免费用户可以体验接入豆包2.1 Turbo模型的办公任务模式。
6月17日,X 上 OpenAI Codex 团队负责人 Tibo(@thsottiaux)发了一条推文,提醒大家 Codex App、CLI 和 SDK 现在可以接任何开源模型,不只限于 OpenAI 自己的模型。
依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?

硬氪获悉,雪梦未来(SnowOrigin)团队获得龚虹嘉、陆奇及海外机构投资。这支北大背景团队以sEMG(表面肌电)运动神经信号解码技术为切入点,通过神经腕带、第一视角采集设备以及自研NMH(Neural Math Hybrid)AI解码模型,构建新一代面向具身智能的人类操控数据采集方案。