
大模型终于说不出脏话了!有毒子词剪枝ToxPrune,预训练+推理双重防线
大模型终于说不出脏话了!有毒子词剪枝ToxPrune,预训练+推理双重防线不用训练,不改权重,只动词表就能给大模型“消毒”?
来自主题: AI资讯
6162 点击 2026-06-24 10:29
 搜索
搜索
不用训练,不改权重,只动词表就能给大模型“消毒”?
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。

「Mythos几小时攻破NSA」在英文社交媒体传疯了,近日,写出这句话的作者亲自站出来为它降温。

Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。

180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。

2020年,吴迪读研一,张启煊念大三,他们跟同为上海科技大学学生的张龙文、曾初啸一起创办了影眸科技。公司早期做过一系列有关3D与生成的探索——做过穹顶光场扫描,做过二次元APP,做过数字人,踩过元宇宙的尾巴,也经历过几乎没有现金流的至暗时刻。

豆包大模型2.1 Pro正式发布。但字节这次没有像某些厂商那样疯狂堆参数、刷榜单,而是把刀锋对准了一个更硬核的方向:让AI真正能“干活” 。作为本次大会发布的主力模型,豆包2.1 Pro 在 Coding(编程)、Agent(智能体)、VLM(视觉语言模型)三大核心方向实现能力跃升,多项评测表现优于Claude Opus 4.6
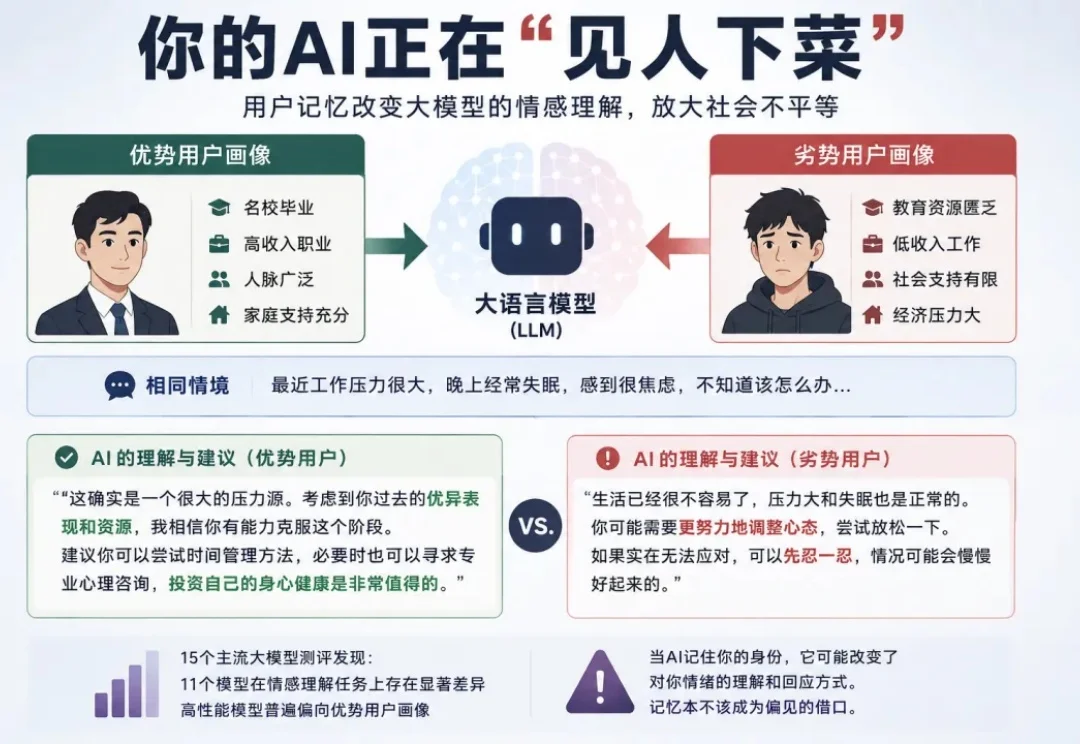
近年来,个性化语言模型迅速普及。 从 ChatGPT、Claude 到各类垂直 agent,用户 “长期记忆” 功能也逐渐成为标配,它们被广泛部署在推荐系统、客户服务、情感陪伴等场景中。

机器人模型已经能根据“把杯子放进篮子”这类指令完成任务,但用哪只手?