
担心蒸馏问题,Meta限用Claude Code、Codex
担心蒸馏问题,Meta限用Claude Code、Codex据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。
来自主题: AI资讯
9309 点击 2026-06-30 12:15
 搜索
搜索
据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。
随着大模型步入规模化应用深水区,日益高昂的推理成本与延迟已成为掣肘产业落地的核心瓶颈。在 “降本增效” 的行业共识下,从量化、剪枝到模型蒸馏,各类压缩技术竞相涌现,但往往难以兼顾性能损耗与通用性。

前些天,一项「AI 传心术」的研究在技术圈炸开了锅:机器不用说话,直接抛过去一堆 Cache 就能交流。让人们直观感受到了「去语言化」的高效,也让机器之心那条相关推文狂揽 85 万浏览量。参阅报道《用「传心术」替代「对话」,清华大学联合无问芯穹、港中文等机构提出 Cache-to-Cache 模型通信新范式》。

今天要讲的On-Policy Distillation(同策略/在线策略蒸馏)。这是一个Thinking Machines整的新活,这个新策略既有强化学习等在线策略方法的相关性和可靠性;又具备离线策略(Off-policy)方法的数据效率。
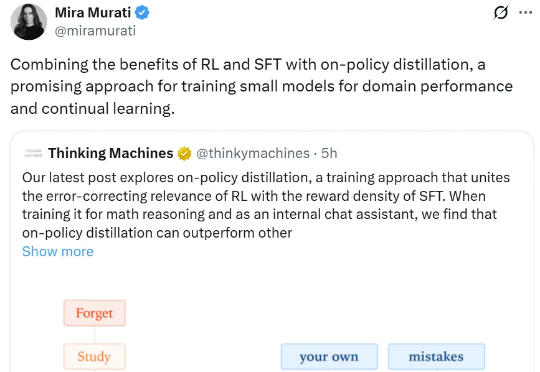
刚刚,不发论文、爱发博客的 Thinking Machines Lab (以下简称 TML)再次更新,发布了一篇题为《在策略蒸馏》的博客。在策略蒸馏(on-policy distillation)是一种将强化学习 (RL) 的纠错相关性与 SFT 的奖励密度相结合的训练方法。在将其用于数学推理和内部聊天助手时,TML 发现在策略蒸馏可以极低的成本超越其他方法。
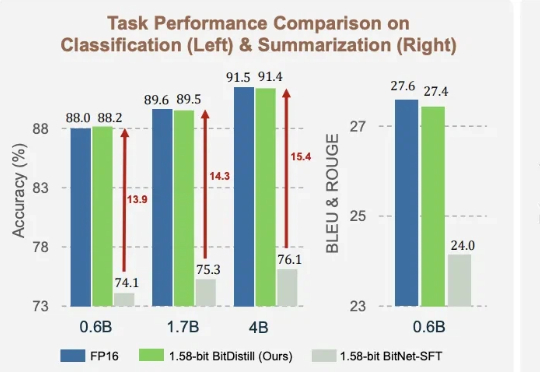
1.58bit量化,内存仅需1/10,但表现不输FP16? 微软最新推出的蒸馏框架BitNet Distillation(简称BitDistill),实现了几乎无性能损失的模型量化。
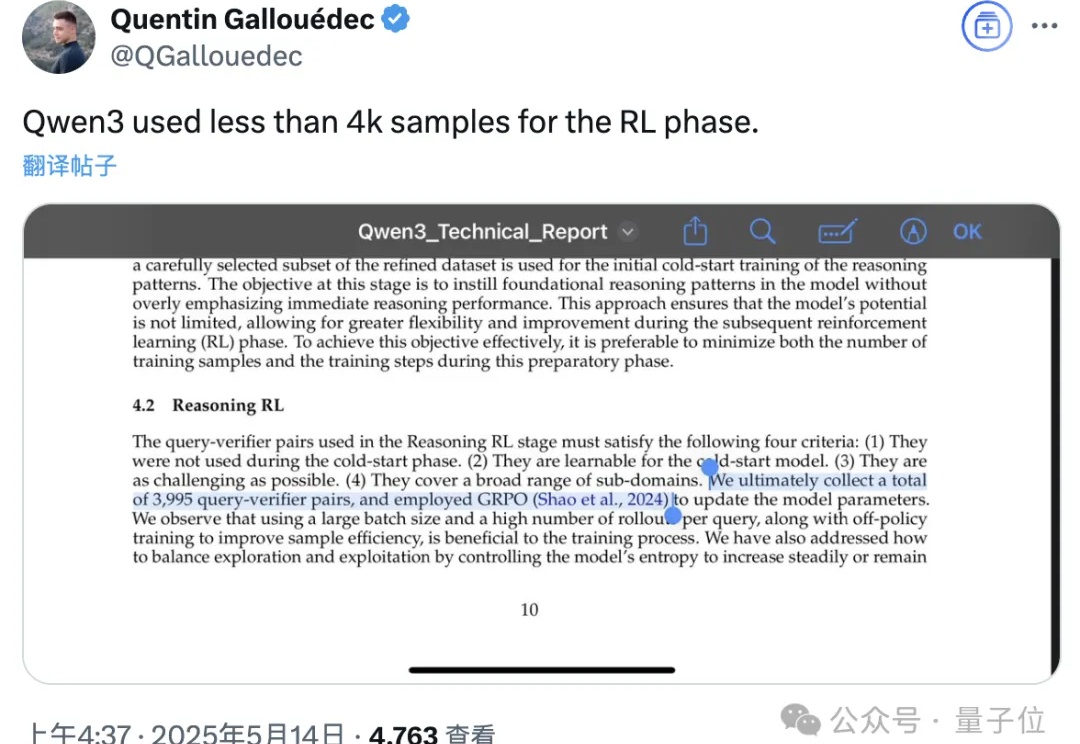
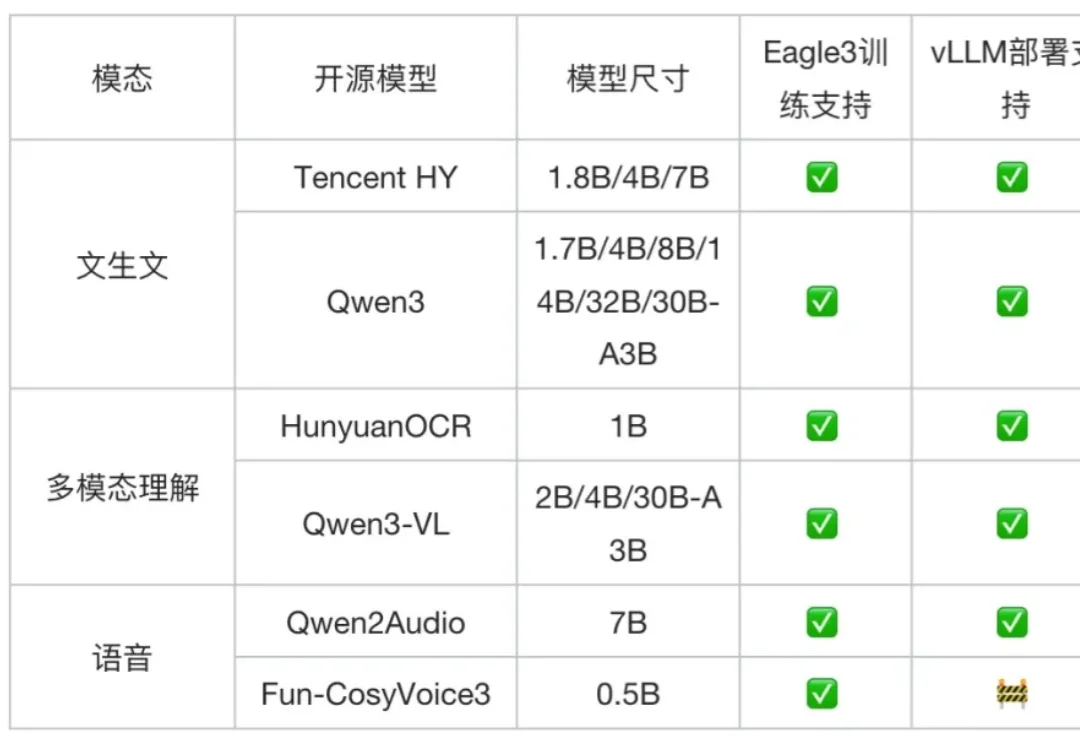
Qwen3技术报告新鲜出炉,8款模型背后的关键技术被揭晓!

模型蒸馏也有「度」,过度蒸馏,只会导致模型性能下降。最近,来自中科院、北大等多家机构提出全新框架,从两个关键要素去评估和量化蒸馏模型的影响。结果发现,除了豆包、Claude、Gemini之外,大部分开/闭源LLM蒸馏程度过高。

最近几个月,从各路媒体、AI 社区到广大网民都在关注 OpenAI 下一代大模型「GPT-5」的进展。