T-PAMI|中国科大、合工大等提出CAPER++:让关节物体位姿感知真正迈向「又快又稳」
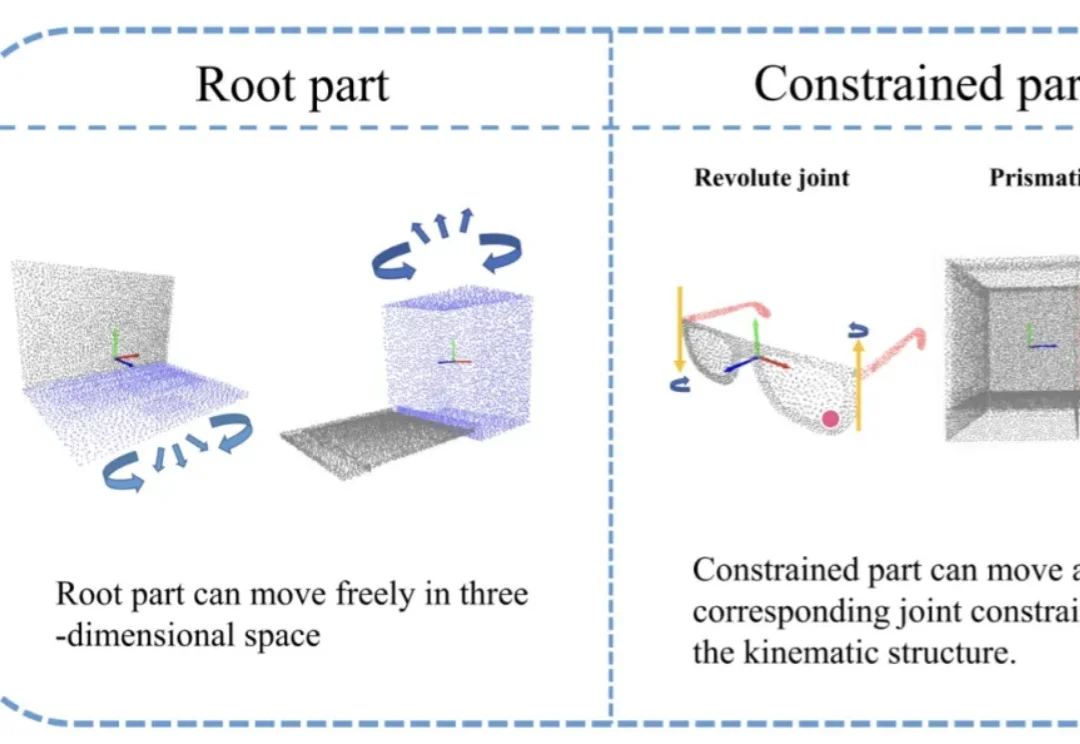
T-PAMI|中国科大、合工大等提出CAPER++:让关节物体位姿感知真正迈向「又快又稳」在具身智能快速发展的今天,机器人已经不再满足于「看见」刚体物体,而是开始真正走向复杂环境中的交互与操作。从机械臂开柜门,到服务机器人整理抽屉,再到工业场景中的工具操作,大量真实世界目标都属于关节物体(Articulated Objects)。
来自主题: AI技术研报
8560 点击 2026-05-28 10:18