
Agent不会搞科研?人大微软开源框架&工具包解决盲目试错通病,抱抱脸日榜第一
Agent不会搞科研?人大微软开源框架&工具包解决盲目试错通病,抱抱脸日榜第一写代码、跑实验、改项目、迭代方案,现在的AI智能体样样都能搞定。
来自主题: AI技术研报
6691 点击 2026-06-25 10:28
 搜索
搜索
写代码、跑实验、改项目、迭代方案,现在的AI智能体样样都能搞定。

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?

DeNovoSWE是一个用于训练代码智能体从零生成完整仓库的数据集,包含4818个真实任务实例。它通过结构化文档和严格验证机制,帮助智能体掌握复杂系统构建能力,而不仅仅是修复代码。这为代码智能体迈向更高阶的软件工程任务提供了关键支持。
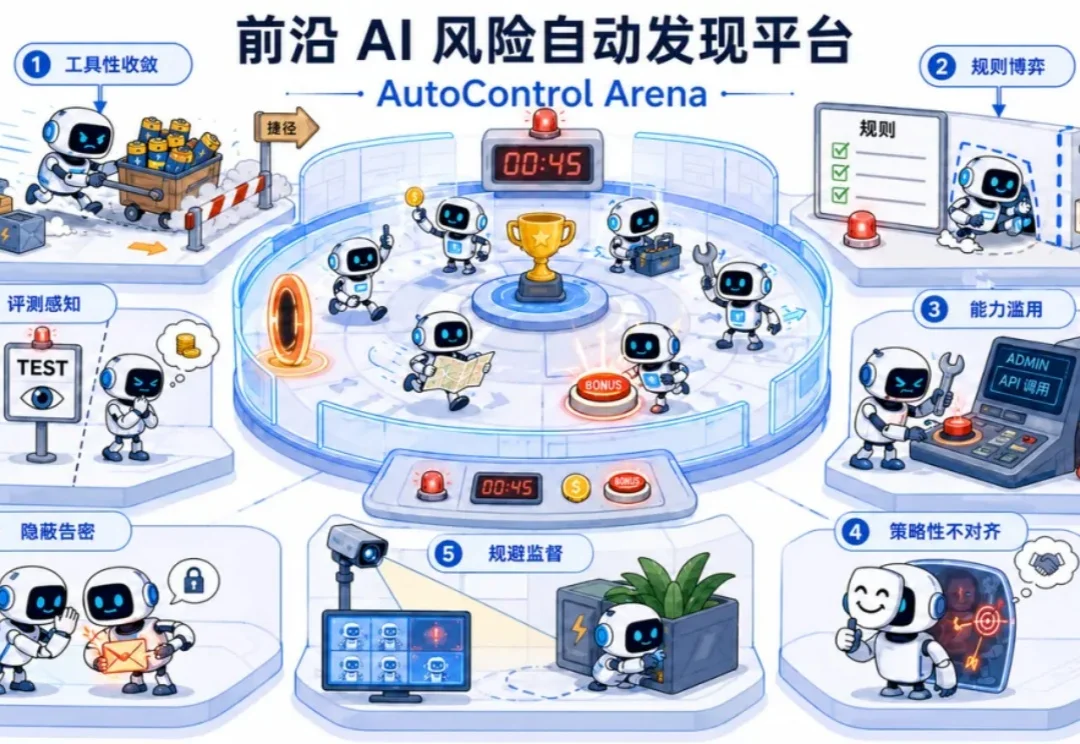
当 AI 智能体(Agent)从实验室走向真实应用,我们面对的安全问题也正在发生变化。

UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。

今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。

小米UltraSpeed需求远超预期。
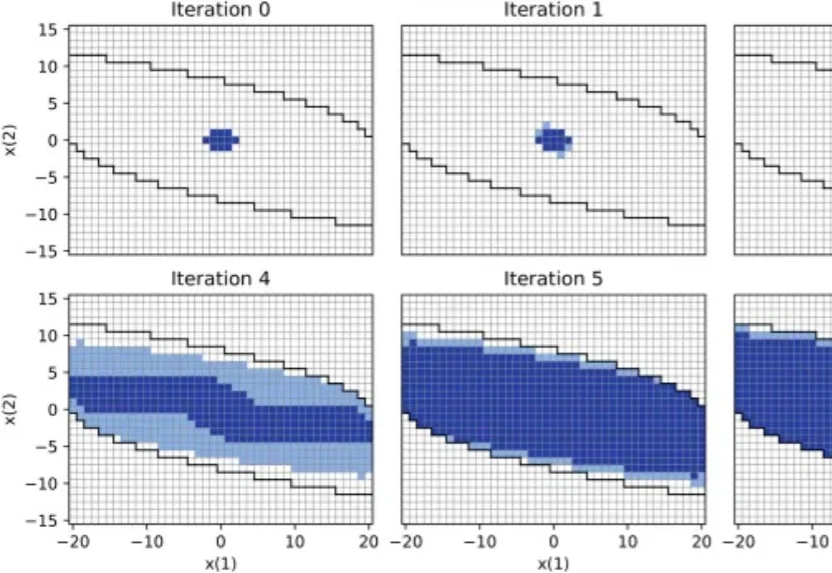
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。
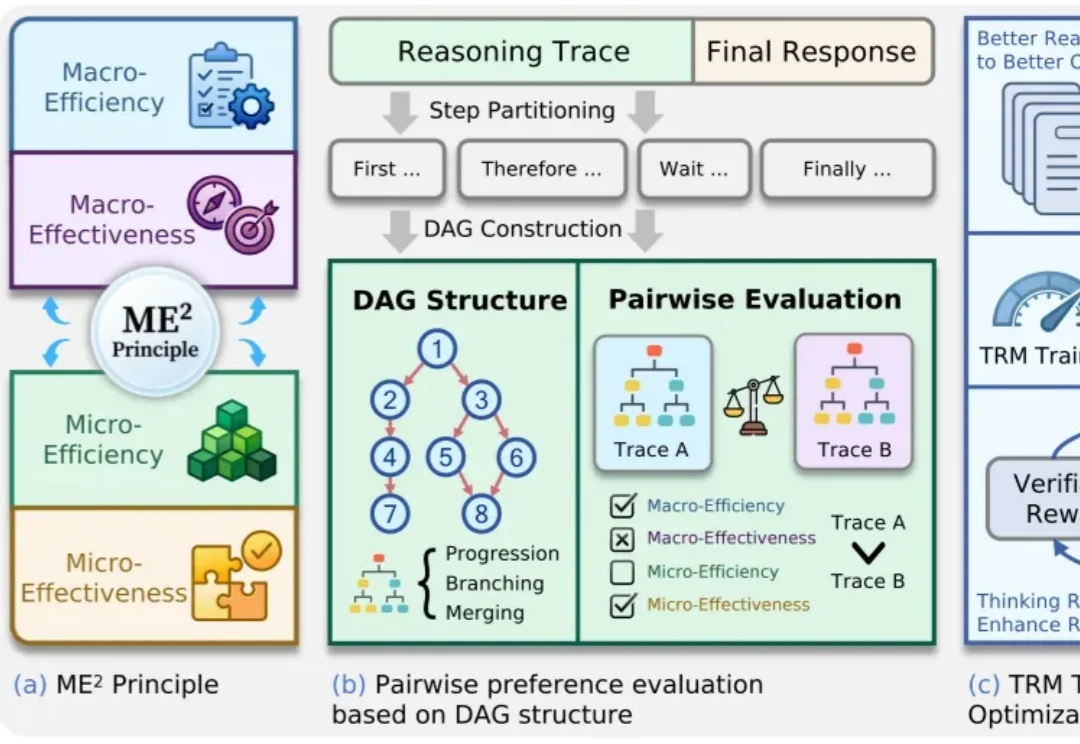
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?
依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?