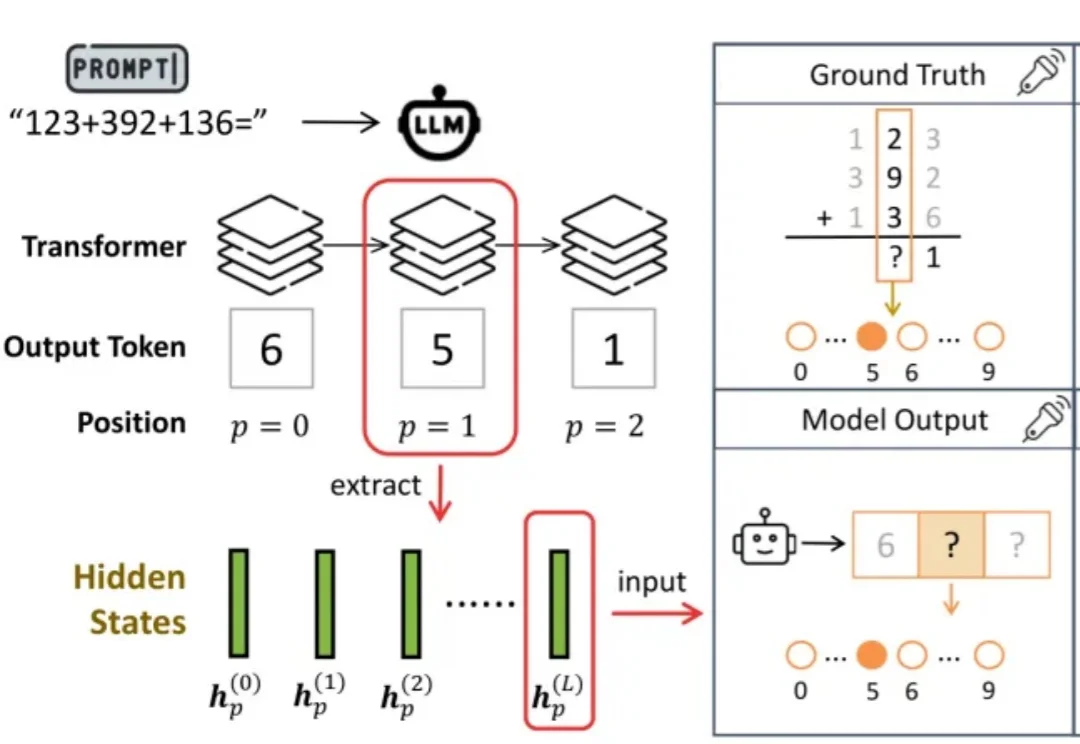
ICML 2026 | 大模型为什么算不对加法?南大团队提出等本位和轨迹,揭示LLM算术错误的几何机制
ICML 2026 | 大模型为什么算不对加法?南大团队提出等本位和轨迹,揭示LLM算术错误的几何机制尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。
来自主题: AI技术研报
7420 点击 2026-06-17 14:05
 搜索
搜索
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。
机器学习已经习惯了处理序列:一句话中的词、视频中的帧、推荐系统中的点击、金融市场中的订单。但在很多真实场景里,数据并不是按固定步长排好队出现的。

当大模型开始控制机械臂、家用机器人时,“安全”这件事也变得不一样了。
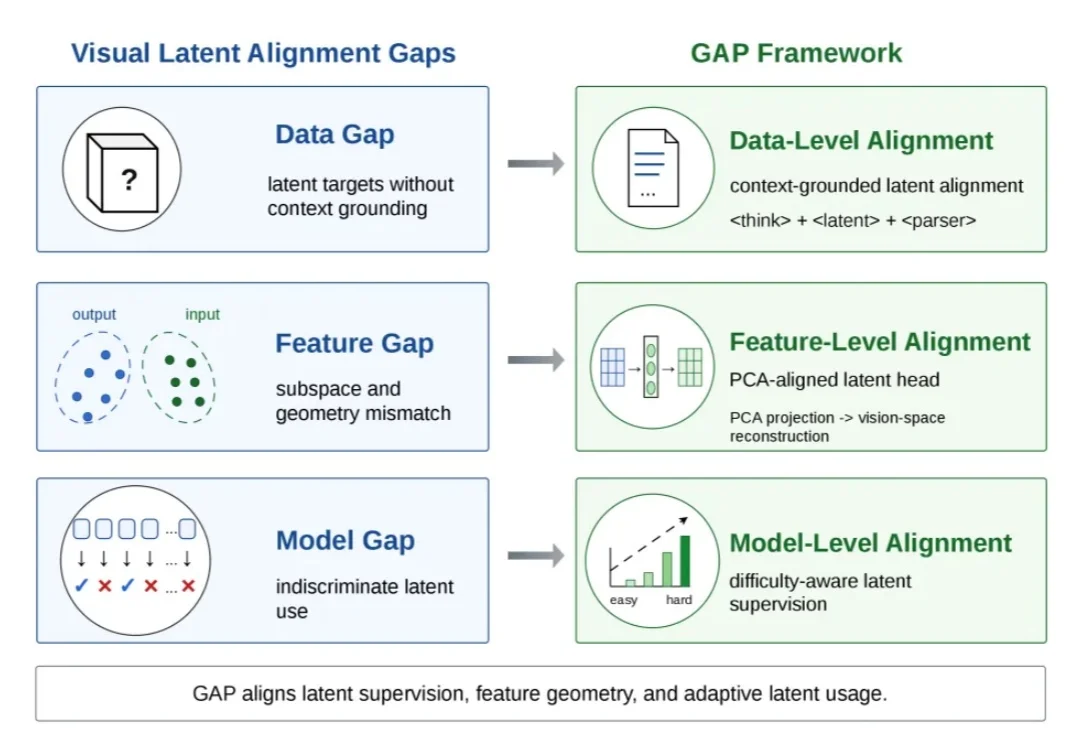
导读:视觉 latent reasoning 希望让多模态模型在内部生成连续 latent token,用这些中间表示补充多模态理解和推理任务中缺失的视觉证据。但问题在于,模型生成出来的 latent token 可能并不落在它原本熟悉的视觉输入空间里;如果模型无法稳定读取这些 token,它们就很难成为有效的中间视觉证据。

当用户给出一句简单提示词时,当前的音视频生成模型往往已经能够生成具有不错质量的视听内容。然而,一旦提示词变得复杂,问题便开始暴露出来。
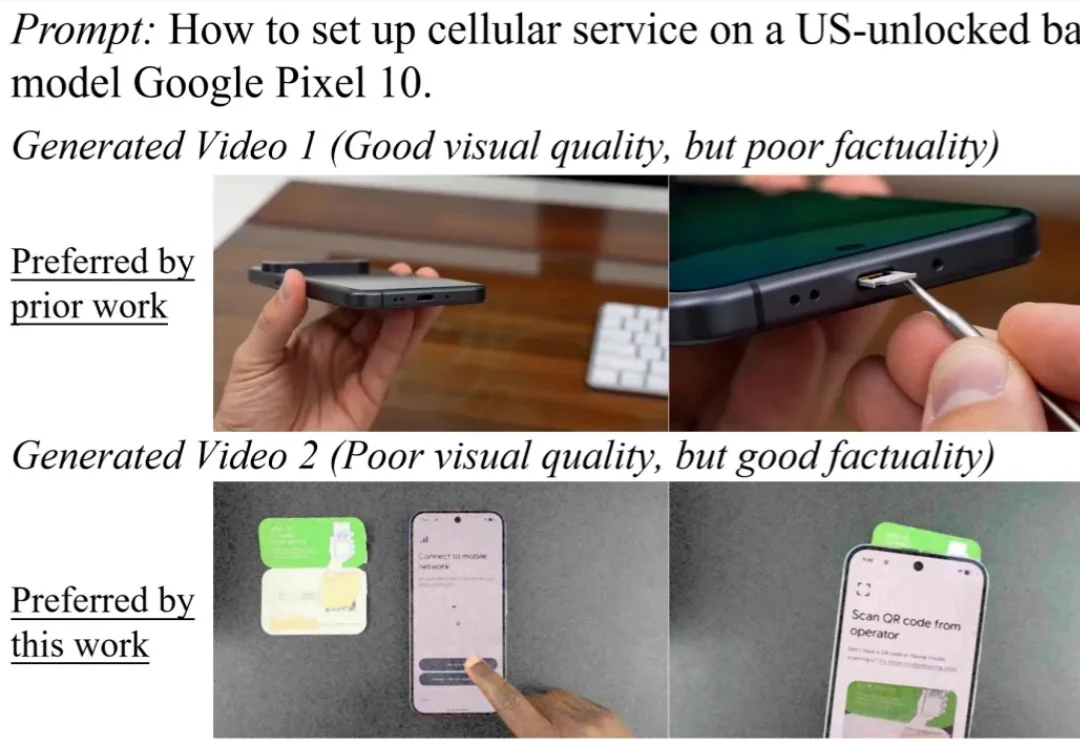
当视频生成模型走出娱乐创作的舒适区,进入科学、医疗、教育等知识密集场景,它们是否还能生成事实准确、清晰可用的视频?

PE-Field将传统的2D位置编码扩展为结构化的3D场,使DiT能够更加直接地在3D空间中处理几何信息。
如果你在三年前问AI圈:未来最强的AI长什么样?

新智元报道 【新智元导读】FuseSearch:学习型自适应并行执行 —— 一个40亿参数的模型,凭什么在代码定位上干过了商用闭源大模型?答案只有四个字:搜得更聪明。 在AI编程狂飙突进的今天,一个尴