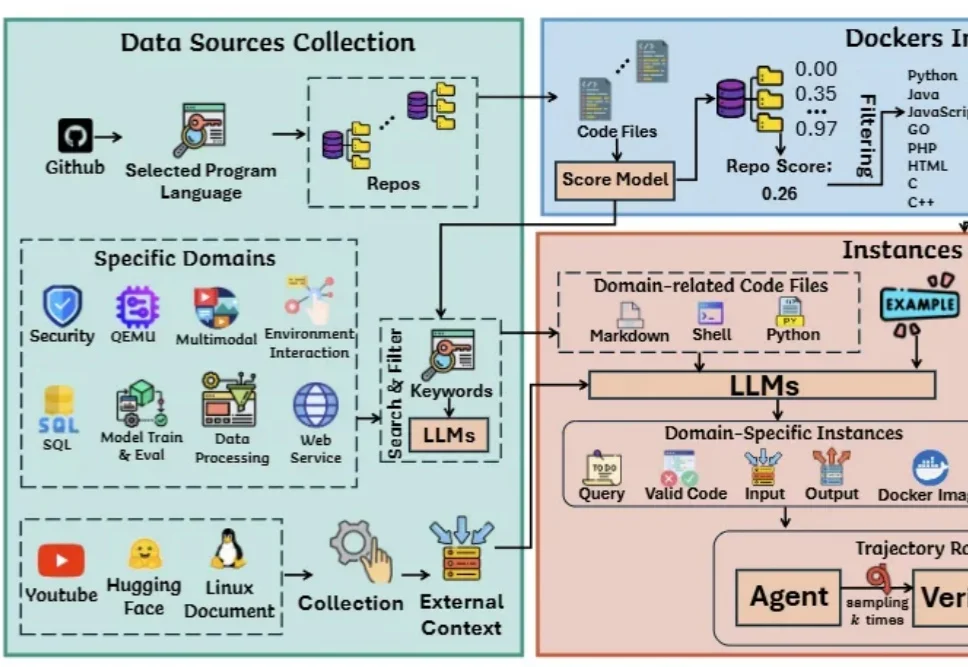
把真实GitHub仓库转化为可执行终端轨迹!TerminalTraj入选ICML 2026
把真实GitHub仓库转化为可执行终端轨迹!TerminalTraj入选ICML 2026被ICML 2026接收为Spotlight!
来自主题: AI技术研报
6715 点击 2026-06-15 13:51
 搜索
搜索
被ICML 2026接收为Spotlight!

如今手机拍照已成日常,后期修图是提升照片质感的关键。
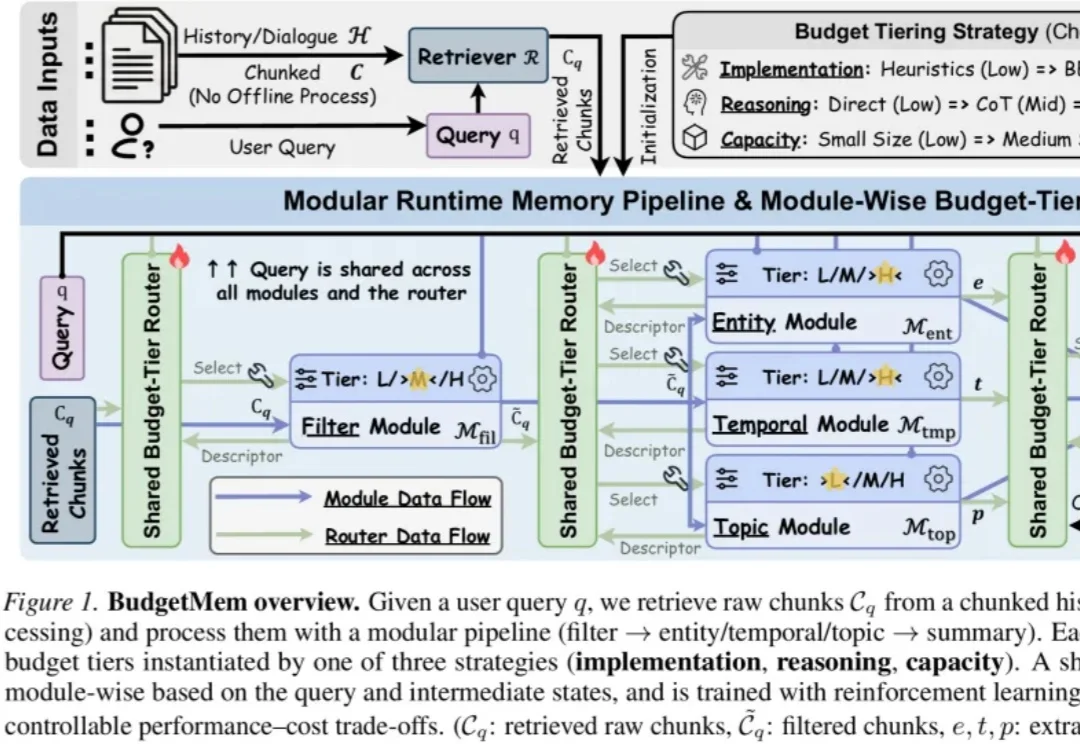
当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。
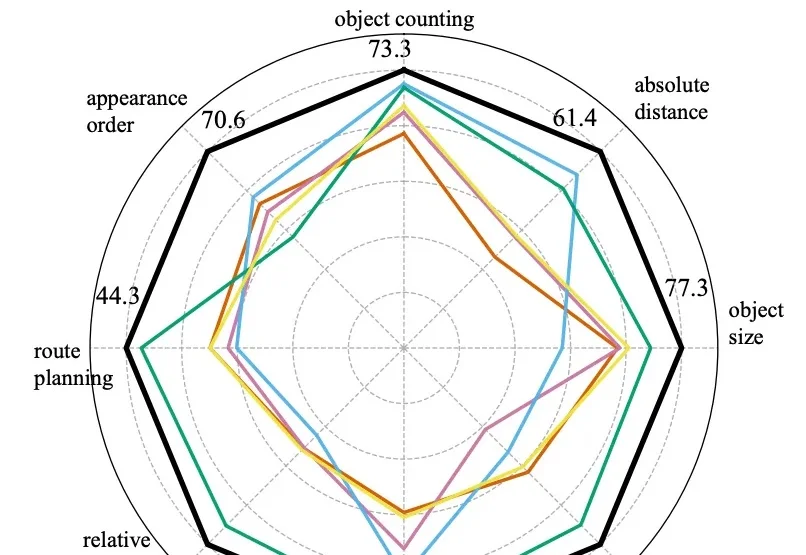
大模型已经能流畅对话、看图识物,但一个更底层的问题始终没被真正解决——它们是否「理解」了我们所处的三维世界?

多模态大模型越来越会读图中文字,但最新研究显示,「读得出来」并不等于「防得住」。西湖大学 AGI Lab 的研究团队发现,当有害文本被渲染成低清、模糊或带噪图片后,模型在一个特定清晰度区间内反而更容易被越狱。
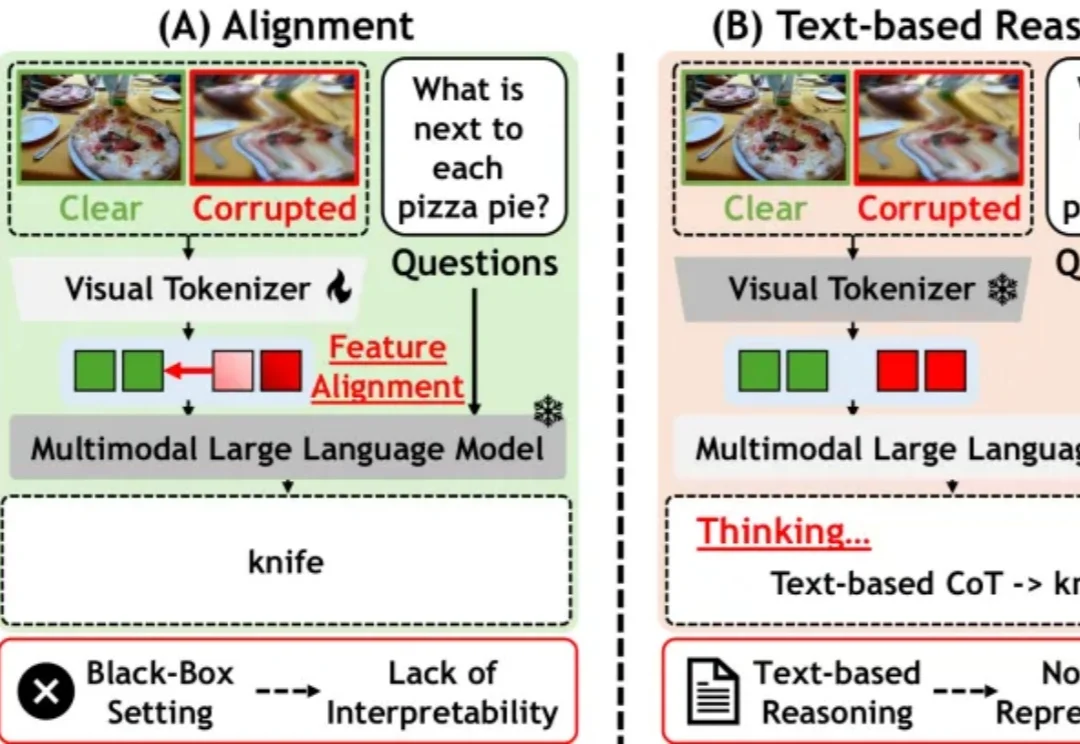
雨雪、雾霾、镜头噪点、压缩失真、夜间弱光……
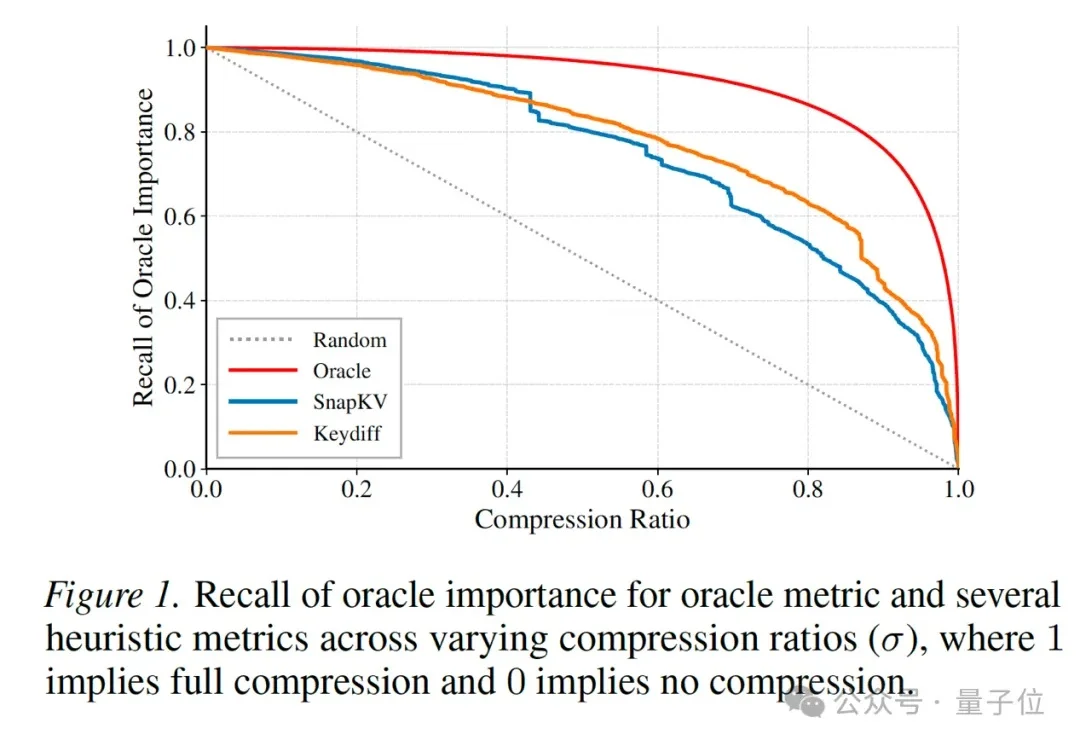
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。
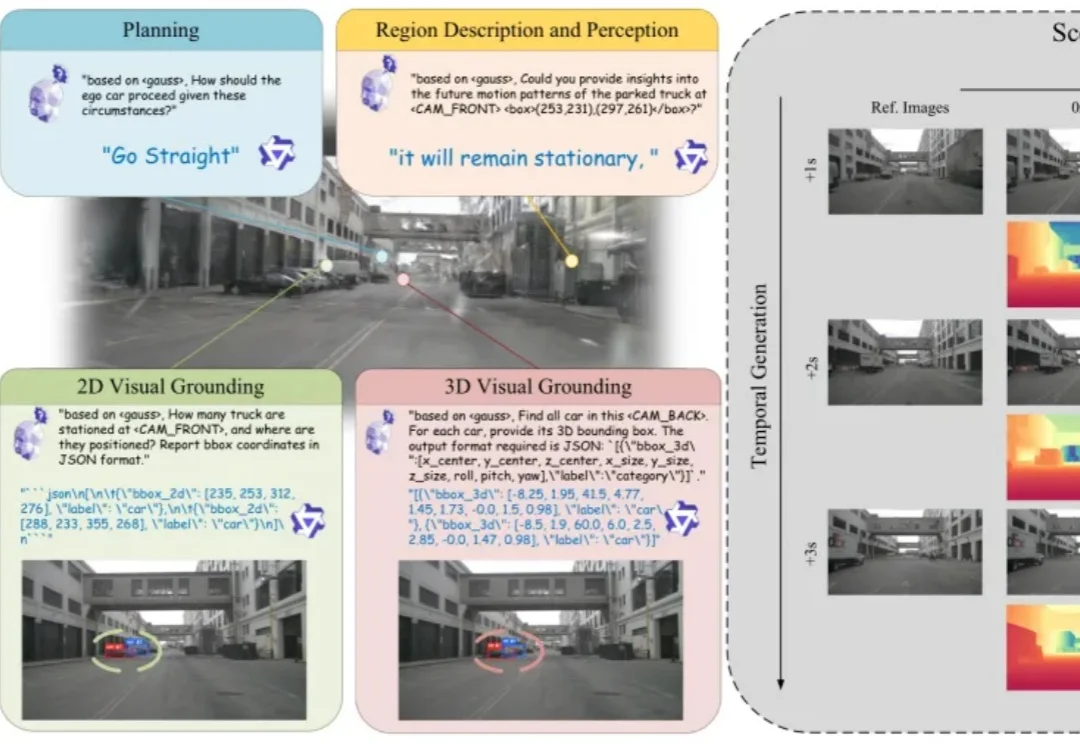
自动驾驶世界模型的研究目标已经从单纯预测未来视觉帧,扩展到构建可用于场景理解、空间定位和后续决策的世界表示。如果模型只能生成外观上合理的未来图像,却无法回答场景中有哪些目标、目标位于何处,以及不同视角下的空间结构如何变化,那么它仍然缺少对三维驾驶环境的显式建模能力。
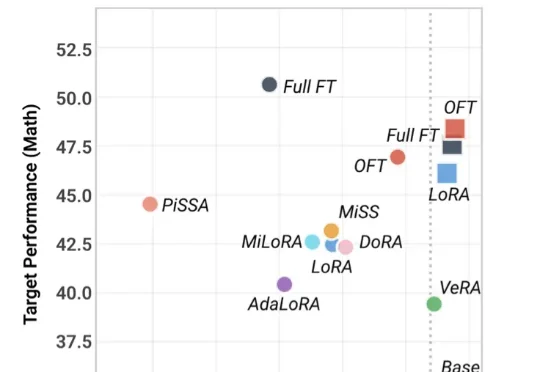
近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。

香港城市大学曾晓成教授与中国石油大学(华东)钟杰教授团队给出了终结级的分子水平证据,成果发表于《Nature Physics》。他们首创了一套无监督深度学习框架,不给AI任何预设条件,直接把海量水系统中7400多万个水分子结构扔给模型,让AI自己去悟。结果不仅直接证明常压水里确实存在两种「暗」组份,还把A/B水分子相互变身的「立交桥」路线图给完整画了出来。