
对话2004年生世界模型创业者陈博远:我不是天才|新皮层
对话2004年生世界模型创业者陈博远:我不是天才|新皮层Yann LeCun的JEPA架构很可能不会work,但至少证明了隐空间比像素或文本空间具备更强的泛化能力;
来自主题: AI资讯
9039 点击 2026-07-01 15:39
 搜索
搜索
Yann LeCun的JEPA架构很可能不会work,但至少证明了隐空间比像素或文本空间具备更强的泛化能力;
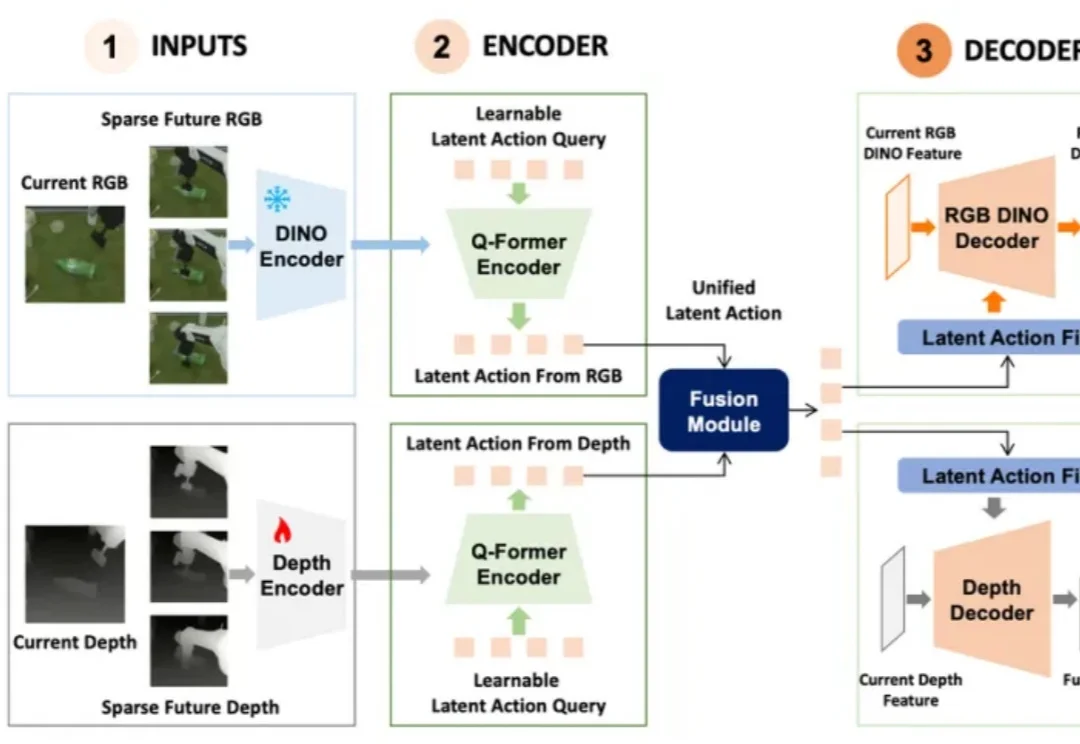
当前,物理 AI 正面临着关于泛化能力的普遍质疑。当模型缺乏对真实物理规律的深度认知、难以跨越复杂多变的开放场景时,如何让机器人真正理解物理世界并精准规划决策,已成为具身智能破局的关键。

这篇来自 Interlatent(一家聚焦具身智能后训练与部署的早期创业公司) 的文章,试图从第一性原理出发,把现代 AI 机器人技术重新讲清楚:一个机器人到底如何理解世界,如何生成动作,又为什么会在数据、延迟和泛化上遇到如此多的困难。

银河通用团队用史上最大、整整 20 亿帧的动捕数据,训练出了全球首个人形机器人全身实时运控基座大模型,该模型零样本泛化全新动作,成功率从 MLP 架构的 76.89% 跃至 92.58%,推理延迟仅 0.39ms,效果超越英伟达 SONIC,甚至比目前业内主流 TWIST 系统速度提升至五倍。
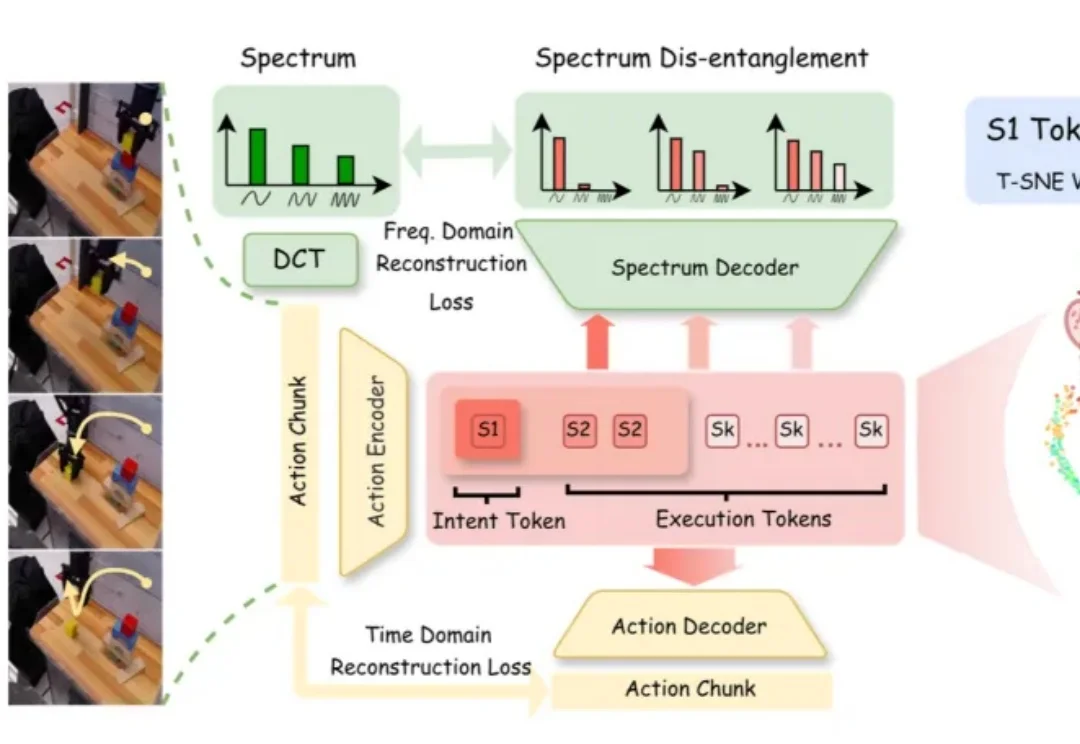
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。

在具身智能最难的泛化问题上,他们连续拿出顶会级成果,并把它们沉淀进其创新 VLOA 大模型,推动机器人迈向广阔现实。
“完全抛弃传统的代码编辑器,我直接告诉 AI 去修改代码。”

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。
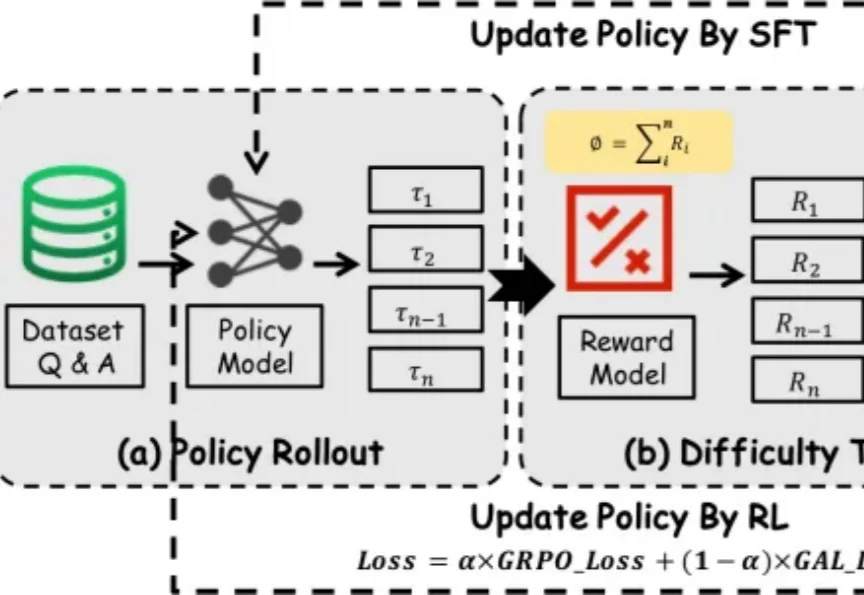
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。

具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。