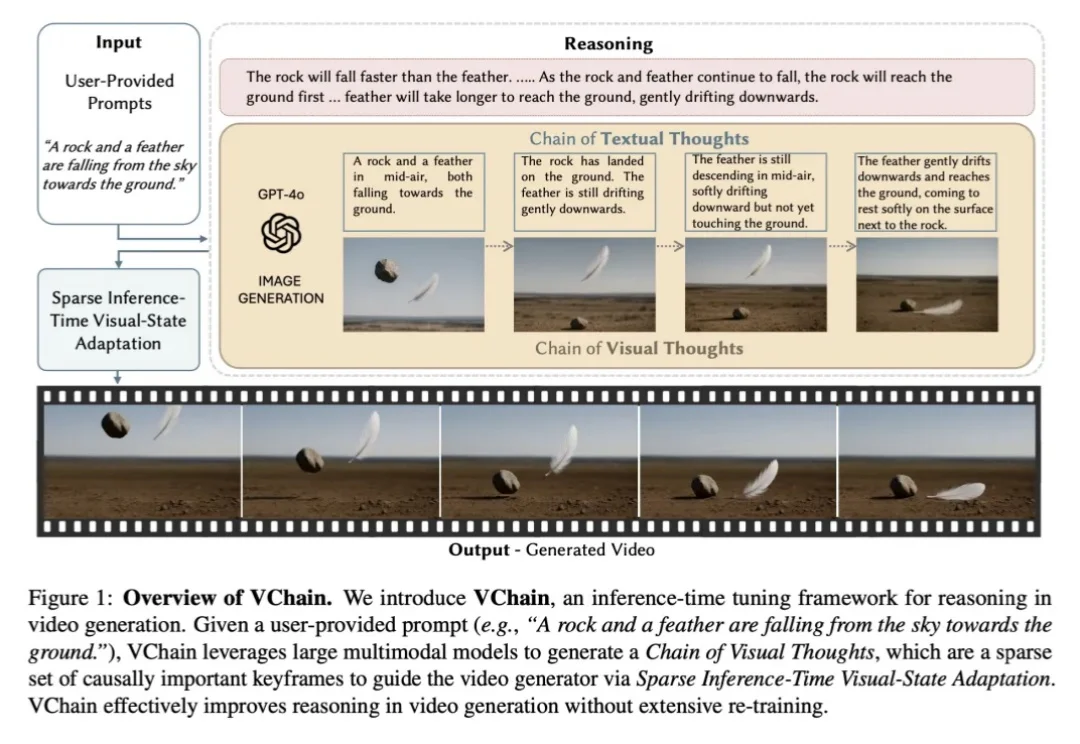
京东开源音视频生成框架JoyAI-Echo,5分钟叙事角色不崩,声音不乱,秒出片
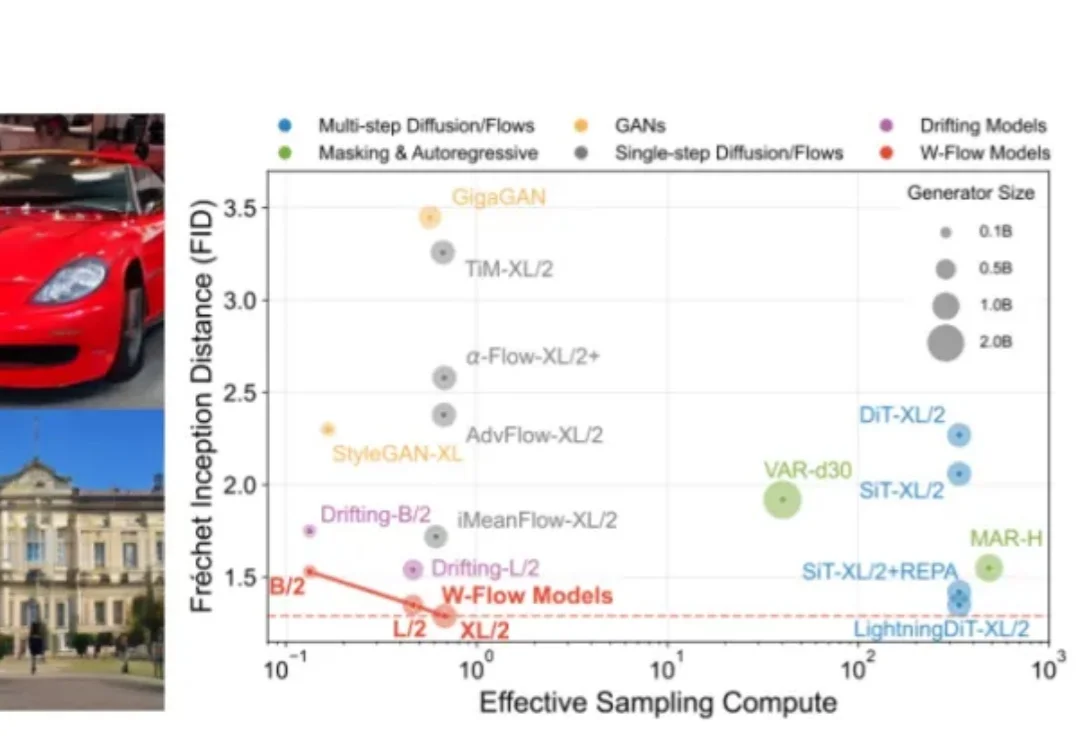
京东开源音视频生成框架JoyAI-Echo,5分钟叙事角色不崩,声音不乱,秒出片京东首次开源长音视频生成框架JoyAI-Echo。它直击长视频生成中的角色一致性、声音稳定性和生成速度三大核心难题,一举在多个核心指标上超越行业标杆模型。根据公开评测结果,JoyAI-Echo在跨镜头一致性、语音准确率、用户偏好等关键指标上均取得领先表现,与业内主流长视频生成模型相比优势明显,出道即跻身全球第一梯队。
来自主题: AI资讯
8830 点击 2026-06-05 22:06