
担心蒸馏问题,Meta限用Claude Code、Codex
担心蒸馏问题,Meta限用Claude Code、Codex据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。
来自主题: AI资讯
9309 点击 2026-06-30 12:15
 搜索
搜索
据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。
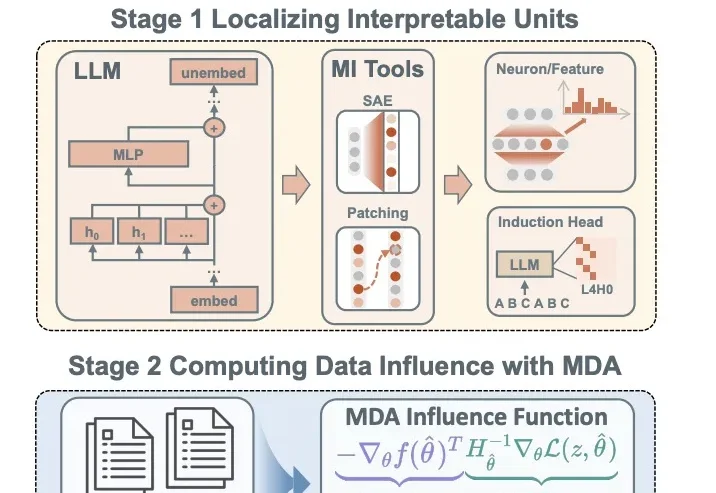
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。

就在最近,OpenAI扔出一篇重磅论文。他们发现,只教AI好好看病,它写代码居然也不作弊了。方法简单到离谱:拿5%的训练数据,教模型在回答健康问题时诚实、谨慎、知错能改。

偷师、借道、换血、误删……折腾到最后,xAI成了给对手供电的人。
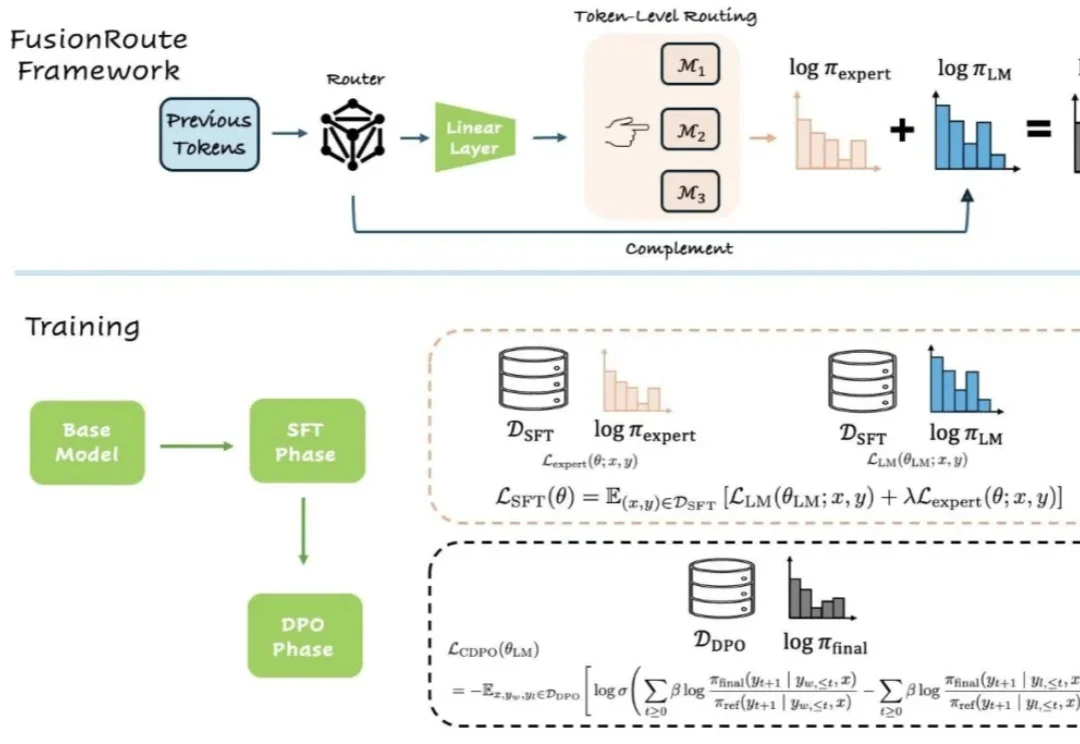
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。
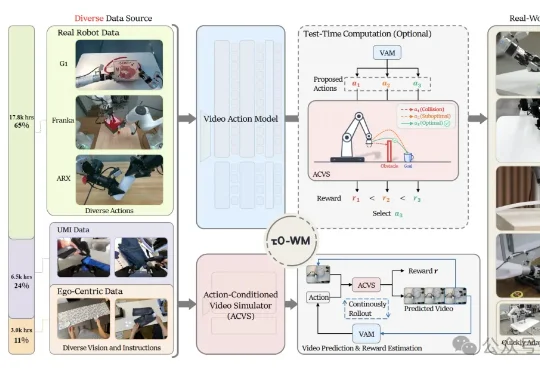
刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。
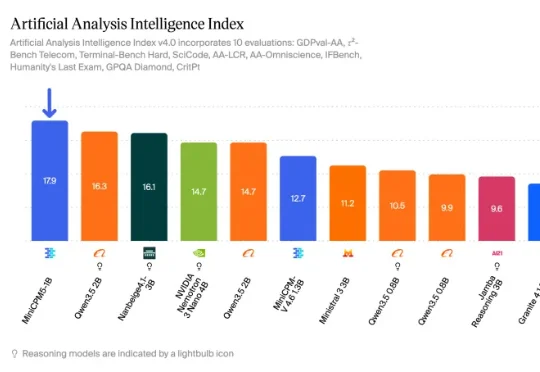
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。一共是两份 L3 级数据集:Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

马斯克深夜官宣:1.5万亿参数Grok V9训练完成,现役三倍!更狠的是,训练数据直接灌入大量Cursor编程交互记录。几乎同一时间,更劲爆的细节浮出水面——训练过程中,xAI往模型里灌入了大量Cursor编程数据。
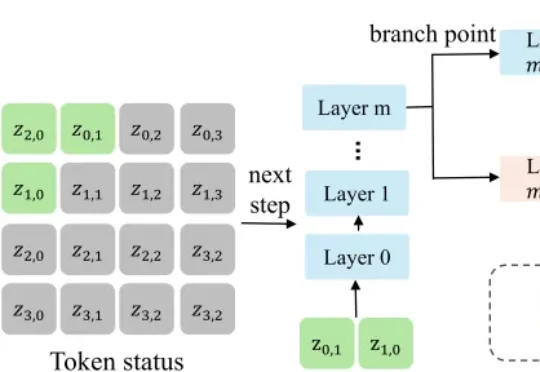
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR—— 一个轻量级的后训练加速框架。不需要从头训练,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍的端到端加速。