全球首个!「具身原生」世界动作模型LingBot-VA 2.0来了
全球首个!「具身原生」世界动作模型LingBot-VA 2.0来了蚂蚁集团旗下具身智能公司蚂蚁灵波,把这块最难的拼图拍上了桌:LingBot-VA 2.0——行业第一个具身原生预训练模型。所谓「具身原生」,一句话说清楚:不是拿现成的数字世界模型做嫁接,而是从数据、训练目标到模型架构,每一层都为「机器人在物理世界干活」而生—
来自主题: AI资讯
8676 点击 2026-07-10 15:14
 搜索
搜索
蚂蚁集团旗下具身智能公司蚂蚁灵波,把这块最难的拼图拍上了桌:LingBot-VA 2.0——行业第一个具身原生预训练模型。所谓「具身原生」,一句话说清楚:不是拿现成的数字世界模型做嫁接,而是从数据、训练目标到模型架构,每一层都为「机器人在物理世界干活」而生—

如果说扩散世界模型的瓶颈,是每一步去噪都要把同一个大 Transformer 再跑一遍,那么 WorldCache 的思路就是:不要再把所有 Token、所有时间步都当成同一件事。这篇工作把 “哪些内容适合缓存”和“哪些时刻必须重算” 拆开处理,在不重新训练模型、几乎不增加额外显存的前提下,把缓存真正做成了一套更贴合世界模型结构的推理策略。
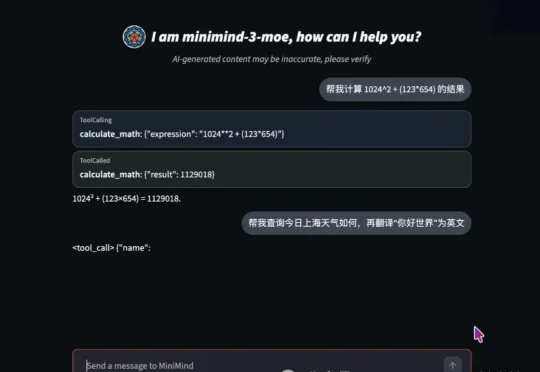
我最近当 AI 班狗刷抖音,一周里被同一个项目推流了三次。项目叫 MiniMind。打开 GitHub,50.4K stars,持续上涨种。这个项目大致就是:几块钱,几个小时,从 0 开始训练一个几十 MB 的小模型。
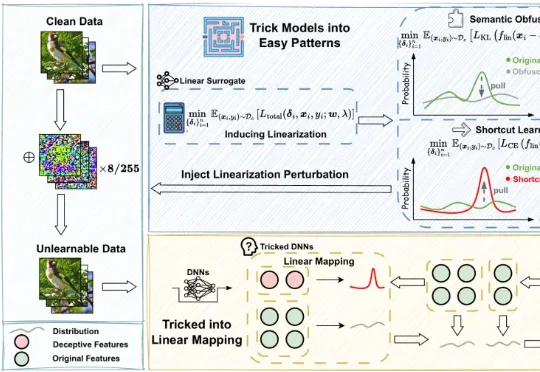
不可学习样本(Unlearnable Examples)是一类用于数据保护的技术,其核心思想是在原始数据中注入人类难以察觉的微小扰动,使得未经授权的第三方在使用这些数据训练模型时,模型的泛化性能显著下降,甚至接近随机猜测,从而达到阻止数据被滥用的目的。

香港中文大学提出了一个全新的算法框架RankSEG,用于提升语义分割任务的性能。传统方法在预测阶段使用threshold或argmax生成掩码,但这种方法并非最优。RankSEG无需重新训练模型,仅需在推理阶段增加三行代码,即可显著提高Dice或IoU等分割指标。
压缩即智能,又有新进展!

近日,北京大学团队提出一个直接基于已有预训练模型进行极低比特量化的通用框架——Fairy2i。该框架通过广泛线性表示将实数模型无损转换为复数形式,再结合相位感知量化与递归残差量化,实现了在仅2比特的情况下,性能接近全精度模型的突破性进展。

AI训练背后,正在上演一场新的「华尔街迁徙」!前银行家纷纷化身AI导师,用自己的专业知识帮助OpenAI、xAI、Scale AI等AI公司训练模型,华尔街精英正在成为AI重塑华尔街的幕后推手。

数据集蒸馏是一种用少量合成数据替代全量数据训练模型的技术,能让模型高效又节能。WMDD和GUARD两项研究分别解决了如何保留原始数据特性并提升模型对抗扰动能力的问题,使模型在少量数据上训练时既准确又可靠。

为破解机器人产业「一机一调」的开发困境,智源研究院开源了通用「小脑基座」RoboBrain-X0。它创新地学习任务「做什么」而非「怎么动」,让一个预训练模型无需微调,即可驱动多种不同构造的真实机器人,真正实现了零样本跨本体泛化。