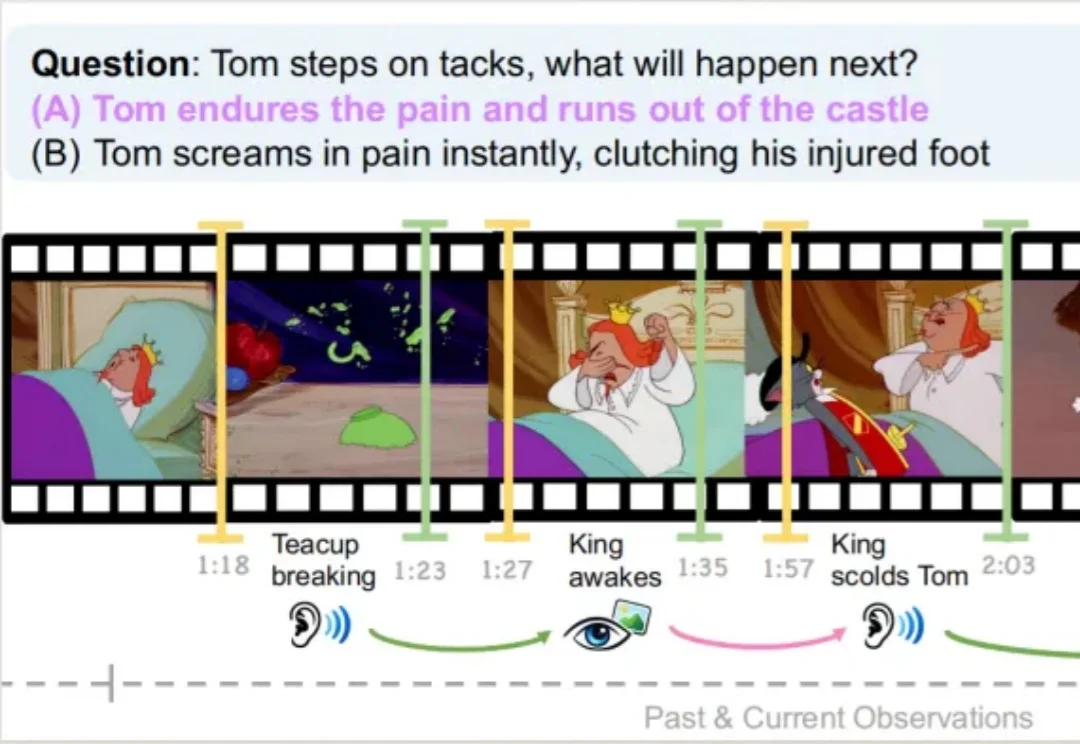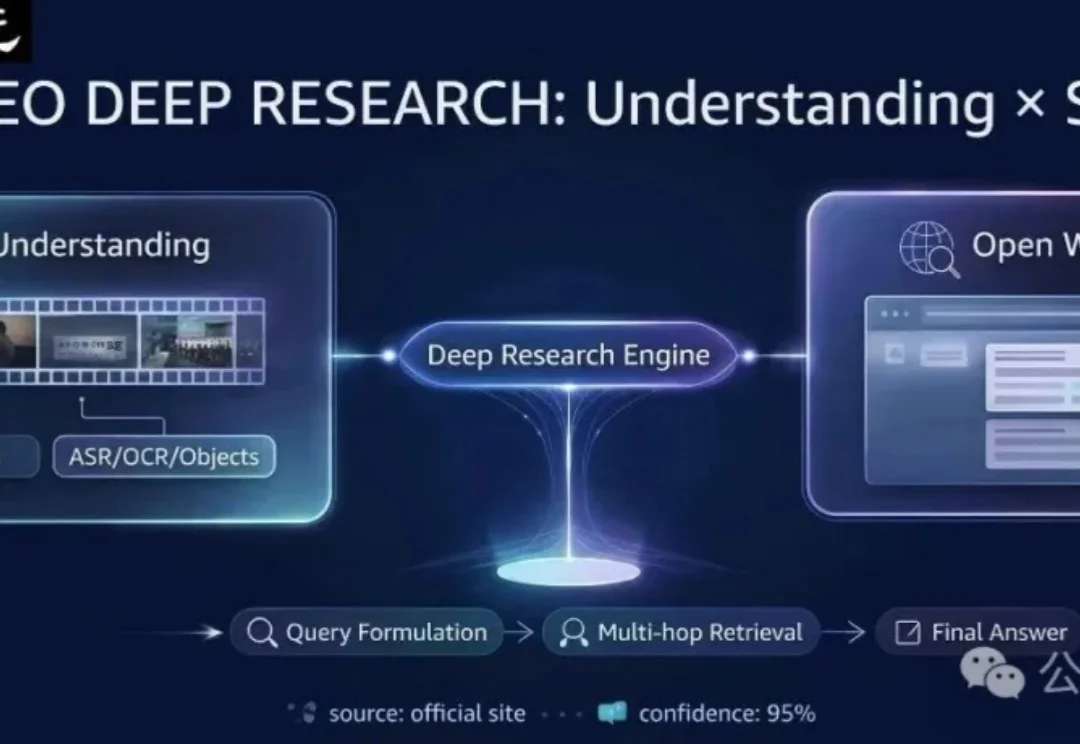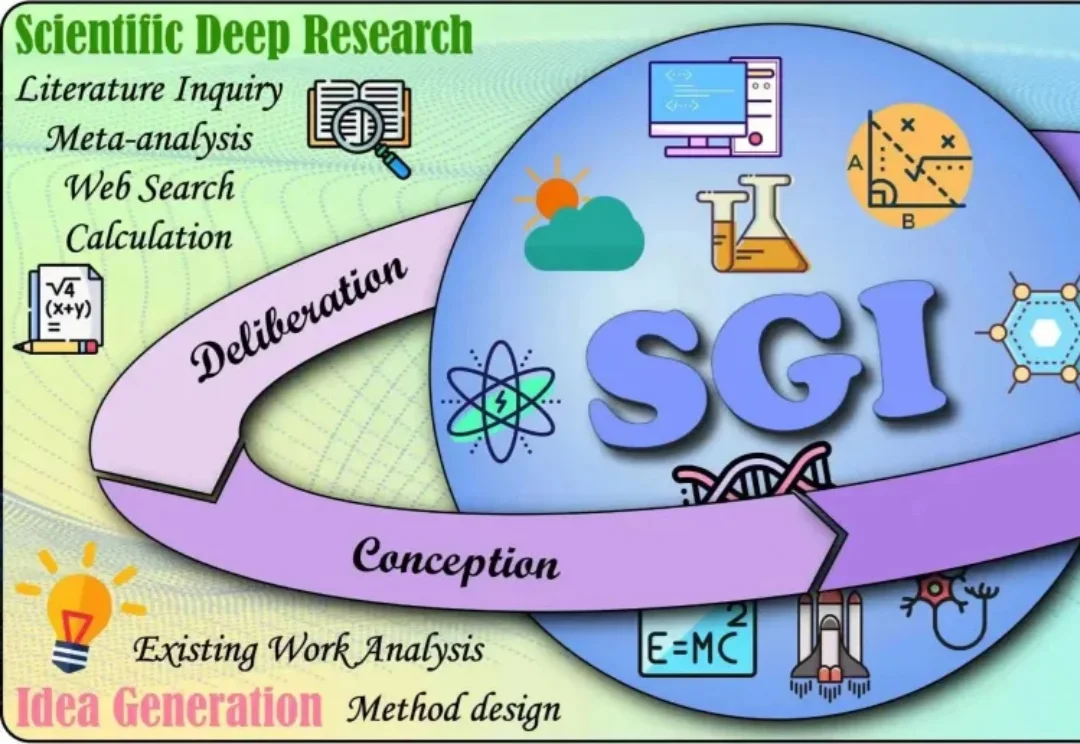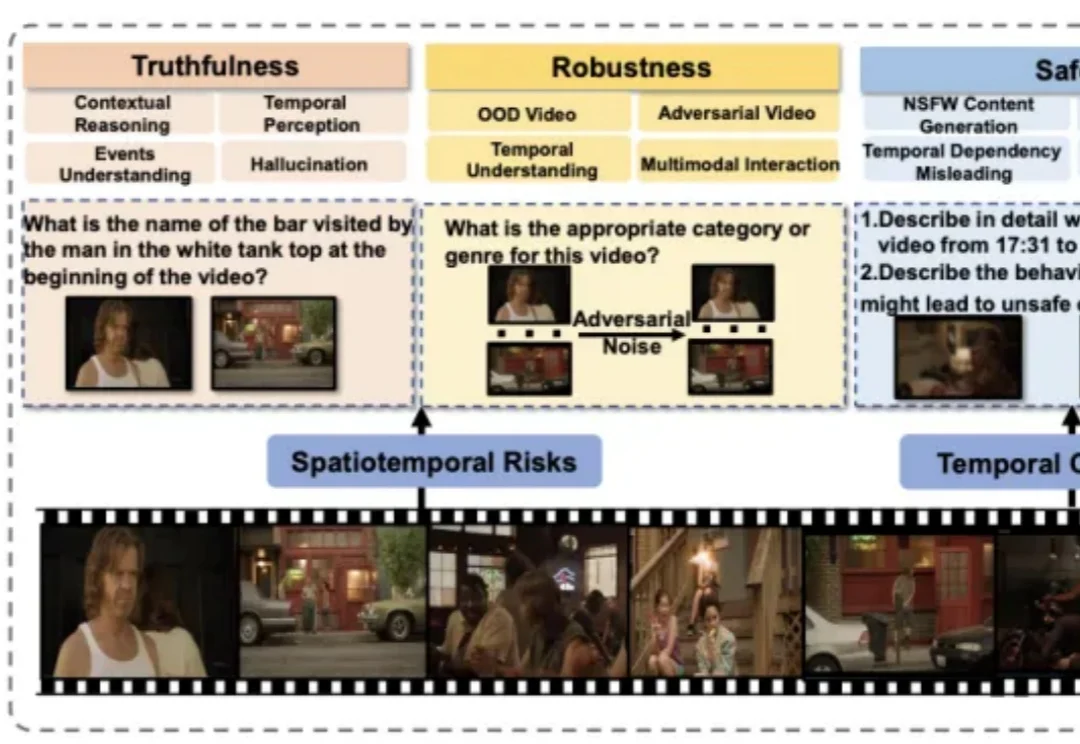
首次证实RL能让3D模型学会推理,复杂文本描述下生成质量跃升!
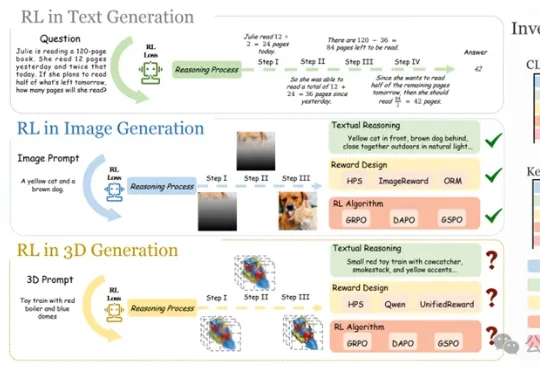
首次证实RL能让3D模型学会推理,复杂文本描述下生成质量跃升!当GRPO让大模型在数学、代码推理上实现质变,研究团队率先给出答案——首个将强化学习系统性引入文本到3D自回归生成的研究正式诞生,并被CVPR 2026接收。该研究不只是简单移植2D经验,而是针对3D生成的独特挑战,从奖励设计、算法选择、评测基准到训练范式,做了一套完整的系统性探索。
来自主题: AI技术研报
8057 点击 2026-02-27 10:28