
Claude「断电」背后:中国基准首次捅开了AI万亿市场「死穴」
Claude「断电」背后:中国基准首次捅开了AI万亿市场「死穴」6月22日Claude全家桶集体宕机,只是冰山一角。当最强大模型被丢进真实机房直面「幽灵故障」,AISHPerf-智算运维智能体评测基准给出残酷答案:全军覆没,无一过50分。这道鸿沟,第一次被量化。
来自主题: AI资讯
6152 点击 2026-06-30 10:21
 搜索
搜索
6月22日Claude全家桶集体宕机,只是冰山一角。当最强大模型被丢进真实机房直面「幽灵故障」,AISHPerf-智算运维智能体评测基准给出残酷答案:全军覆没,无一过50分。这道鸿沟,第一次被量化。

随着全球智能体加速落地,算力需求呈指数级爆发,以 GPU 为核心的 AI 基础设施正变得愈发关键。据摩根士丹利报告预测,2028 年全球 AI 基础设施累计总投资将达 2.9 万亿美元。
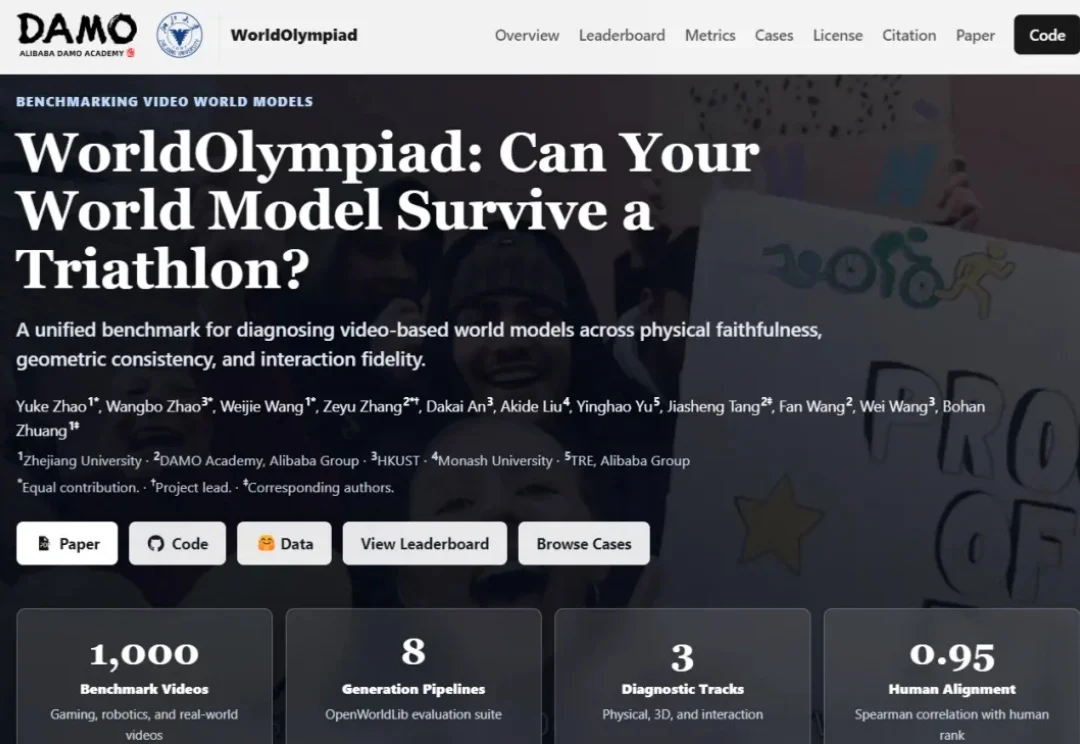
达摩院联合高校推出WorldOlympiad评测基准,跳出传统视频“唯画质”的评价逻辑,以物理真实性、三维几何一致性、长时序交互保真度三大维度,搭配游戏、机器人、通用实景三大场景,打造一套全方位的视频世界模型评测体系。
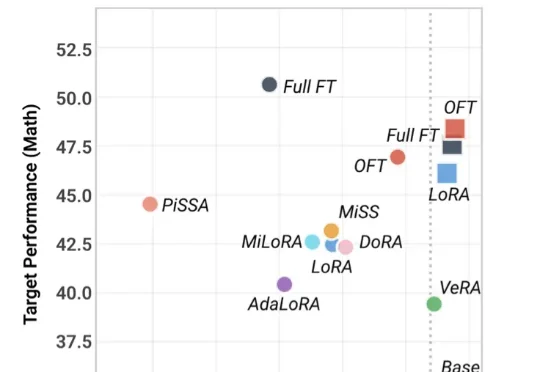
近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。
想象一下,你问 AI 要一个饮食记录工具,它不再是回你一段文字建议,而是直接给你一个可以点击添加、统计热量的完整应用。人和 AI 的交互,正在从「读文字」走向「用应用」。
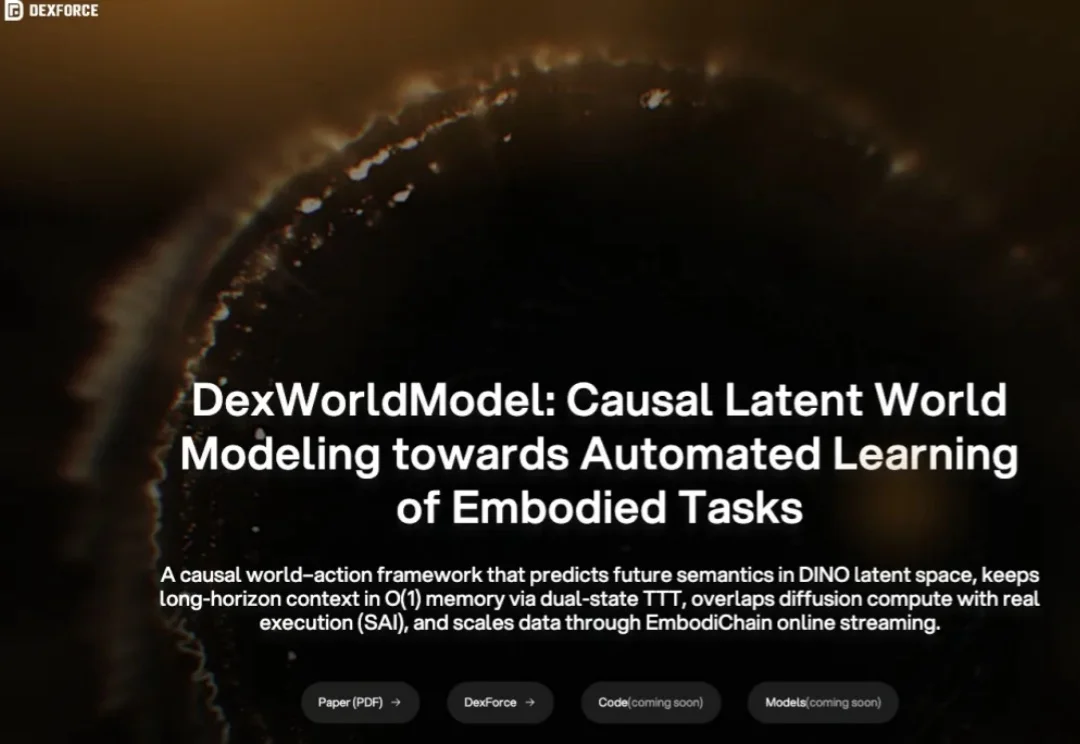
近日,全球具身世界模型权威评测基准 WorldArena 公布最新榜单。在 5 月 25 日截止的最终榜单中,跨维智能登顶 Track 2 赛道全球第一。可以说是,在英伟达、谷歌等全球科技巨头深度布局、重兵把守的世界模型核心腹地,跨维智能实现了强势突围。

李飞飞团队最新发布ESI-Bench——一个专门用来评测具身空间智能的新基准。过去的空间智能评测默认给模型最优观测,而ESI-Bench第一个把观察者变成行动者,闭合了感知-行动回路。
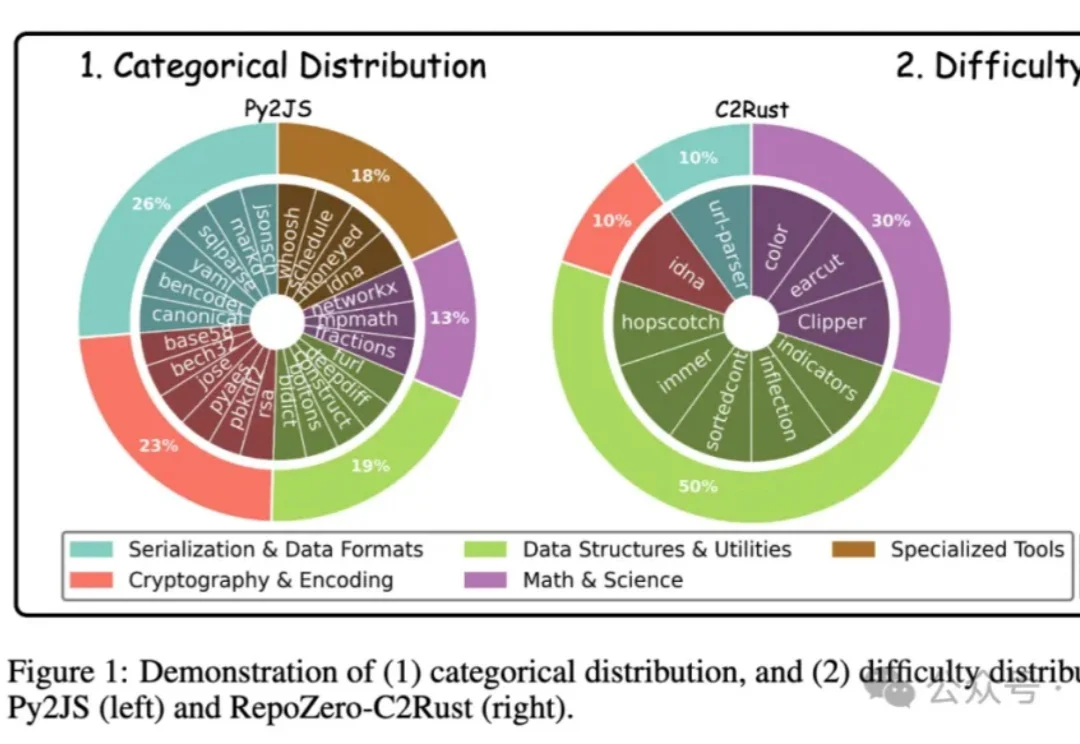
投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。
编程智能体时代,顶流Cursor举旗发布新的评测基准——CursorBench,专门评价Cursor中不同模型谁更“智能体”(即高效执行复杂任务)。关于咋评的这个问题,Cursor还专门撰写了一篇博客。

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。