
C罗刚头球破门,AI解说脱口而出!全模态实时流太狠了
C罗刚头球破门,AI解说脱口而出!全模态实时流太狠了阿里云正式宣布,Apache Flink 3.0全面进入Agentic Streaming For AI时代,并推出全模态数据流处理能力。这是业界第一次,把视频、音频、图像、文本这四类数据,统一放进同一条流式pipeline里调度,让AI能够实时感知、实时理解、实时回应。
来自主题: AI资讯
7459 点击 2026-06-27 12:24
 搜索
搜索
阿里云正式宣布,Apache Flink 3.0全面进入Agentic Streaming For AI时代,并推出全模态数据流处理能力。这是业界第一次,把视频、音频、图像、文本这四类数据,统一放进同一条流式pipeline里调度,让AI能够实时感知、实时理解、实时回应。
昨天,OpenDesign团队(nexu.io)释出了号称html版剪映的‘html-video’项目,完全开源:https://github.com/nexu-io/html-video。基于 hyperframes框架(https://github.com/heygen-com/hyperframes)构建,Apache 2.0 开源,由 Open Design 团队原班人马打造;

刚刚,Cohere放出2180亿参数的MoE大模型Command A+,单张B200可跑,支持48种语言,还带原生引用能力。但这次发布最炸的,不在参数表上,而在那一个许可证:Apache 2.0。
商汤最近做了一件大多数大模型公司都不舍得做的事。每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。
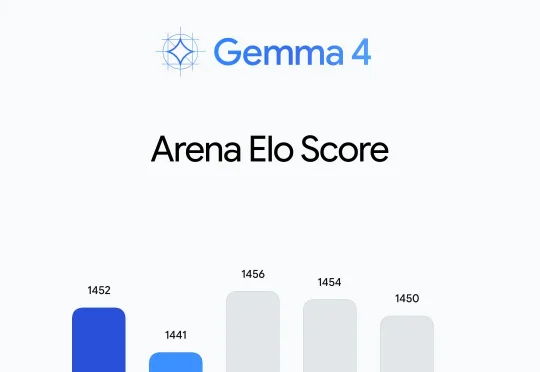
刚刚,谷歌正式发布 Gemma 4,称“这是其迄今为止最智能的开放模型系列”。该系列面向复杂推理与智能体工作流设计,采用商业许可的 Apache 2.0 许可证开源。Gemma 4 提供四种规格:Effective 2B(E2B)、Effective 4B(E4B)、26B 混合专家模型(MoE)和 31B 稠密模型(Dense)。

刚刚,Anthropic神秘王炸Mythos的基准测试泄露了,多项跑分直接刷新纪录!另外,泄露源码中还曝光出卡皮巴拉的细节:代号capabara-v2-fast,支持1M上下文。

3月17日,楽天(乐天)集团正式发布了Rakuten AI 3.0模型,号称是“日本国内最大规模的高性能AI模型”。官方宣传的参数量为约7000亿,并且日语特化,Apache 2.0开源许可,还拿了日本经产省和NEDO的GENIAC项目补助。

在本周一举行的 Open Source Summit Japan 主题演讲中,Linux 基金会执行董事 Jim Zemlin 抛出了一个耐人寻味的判断: “AI 可能还谈不上全面泡沫化,但大模型或许已经开始泡沫化了。”

这是一条门槛最高、监管最严、落地最复杂的赛道,也是人类和 AI 都必须要走的赛道。

刚刚,「欧洲的 DeepSeek」Mistral AI 刚刚发布了新一代的开放模型 Mistral 3 系列模型。该系列有多个模型,具体包括:「世界上最好的小型模型」:Ministral 3(14B、8B、3B),每个模型都发布了基础版、指令微调版和推理版。