
微软的人工智能收入猛增,但长线挑战却早已迫在眉睫
微软的人工智能收入猛增,但长线挑战却早已迫在眉睫微软 ( NASDAQ: MSFT) 2025 年第一季度营收激增,同时还有大规模的人工智能投资(1000 亿美元)。此后,该股表现略逊于市场(标准普尔 500 指数,+3.65%),价格回报率为负 1%。几天前,该公司公布了第二季度业绩。
来自主题: AI资讯
9308 点击 2025-02-12 11:49
 搜索
搜索
微软 ( NASDAQ: MSFT) 2025 年第一季度营收激增,同时还有大规模的人工智能投资(1000 亿美元)。此后,该股表现略逊于市场(标准普尔 500 指数,+3.65%),价格回报率为负 1%。几天前,该公司公布了第二季度业绩。

1/10训练数据激发高级推理能力!近日,来自清华的研究者提出了PRIME,通过隐式奖励来进行过程强化,提高了语言模型的推理能力,超越了SFT以及蒸馏等方法。

最近OpenAI Day2展示的demo可能把ReFT带火了。实际上这不是一个很新的概念,也不是OpenAI原创的论文。 接下来,本文对比SFT、ReFT、RHLF、DPO、PPO这几种常见的技术。
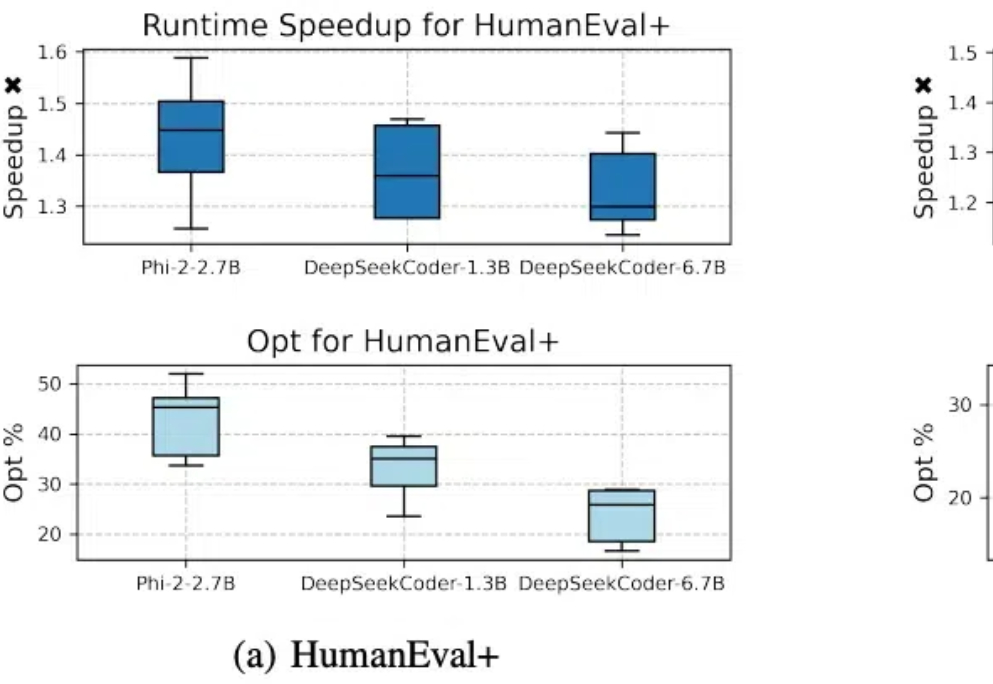
代码模型SFT对齐后,缺少进一步偏好学习的问题有解了。 北大李戈教授团队与字节合作,在模型训练过程中引入偏好学习,提出了一个全新的代码生成优化框架——CodeDPO。
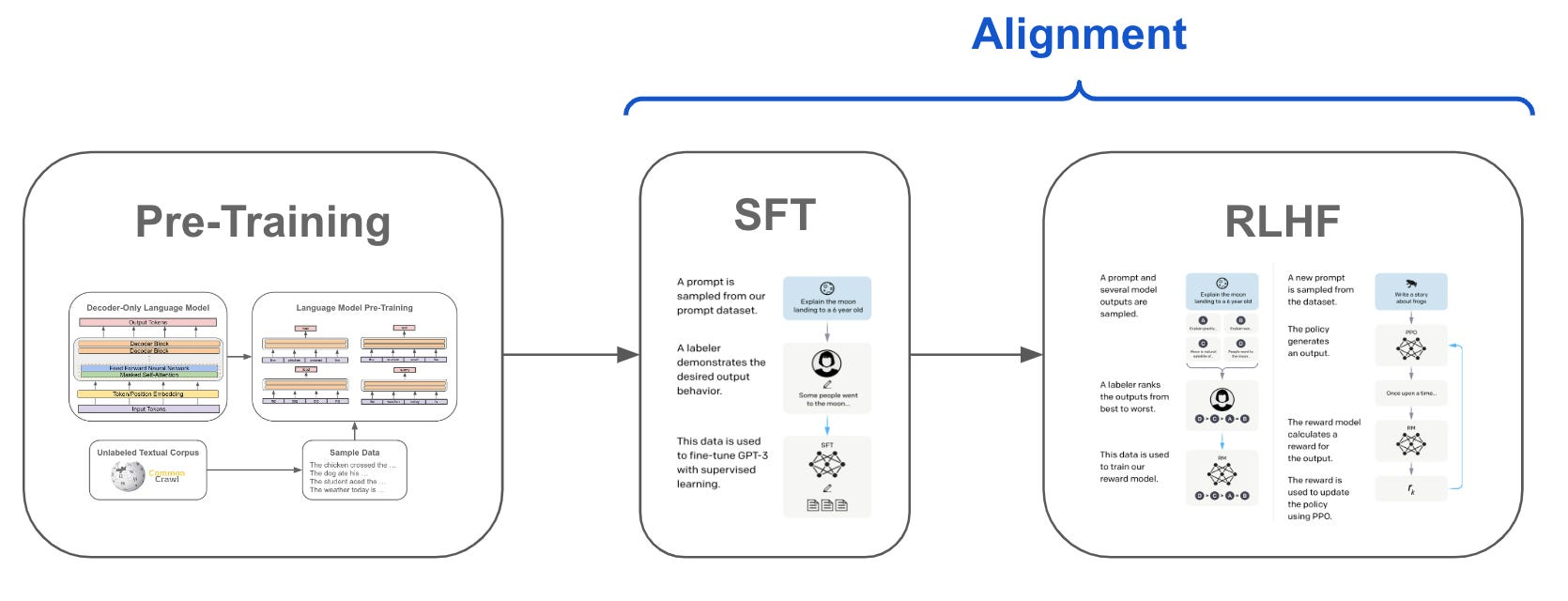
SFT、RLHF 和 DPO 都是先估计 LLMs 本身的偏好,再与人类的偏好进行对齐
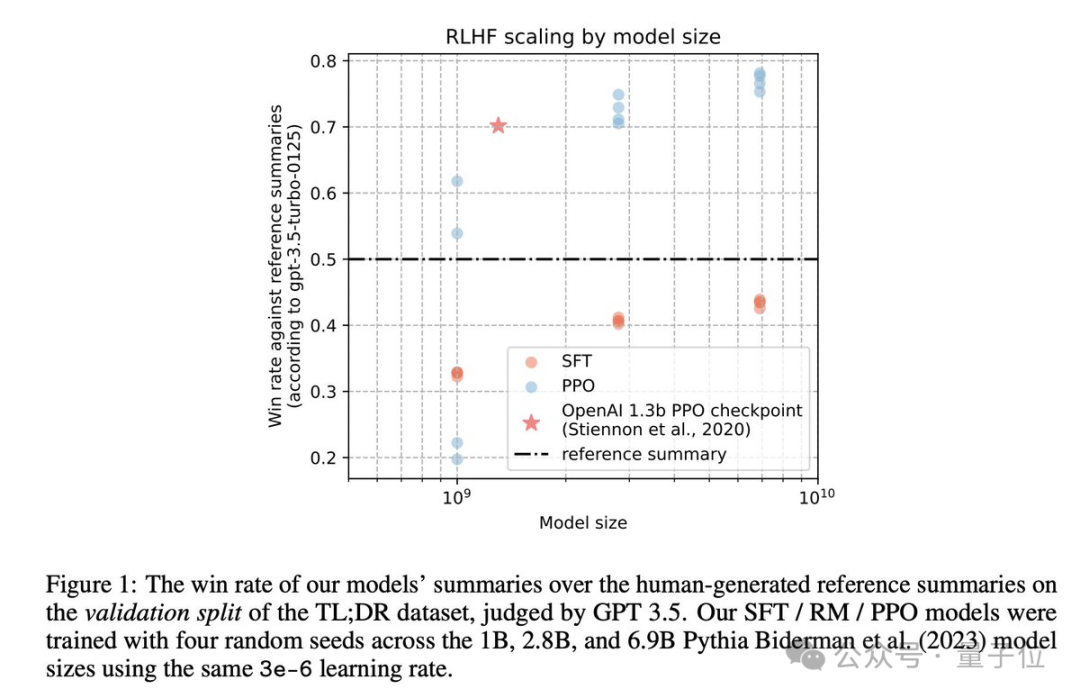
OpenAI的秘密武器、ChatGPT背后功臣RLHF,被开源了。来自Hugging Face、加拿大蒙特利尔Mila研究所、网易伏羲AI Lab的研究人员从零开始复现了OpenAI的RLHF pipeline,罗列了25个关键实施细节。

有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。

近日,美团、浙大等推出了能够在移动端部署的多模态大模型,包含了 LLM 基座训练、SFT、VLM 全流程。也许不久的将来,每个人都能方便、快捷、低成本的拥有属于自己的大模型。

大模型的效果好不好,有时候对齐调优很关键。但近来很多研究开始探索无微调的方法,艾伦人工智能研究所和华盛顿大学的研究者用「免调优」对齐新方法超越了使用监督调优(SFT)和人类反馈强化学习(RLHF)的 LLM 性能。