独家内幕:美团如何用5万张国产卡训出“龙猫”万亿级模型?
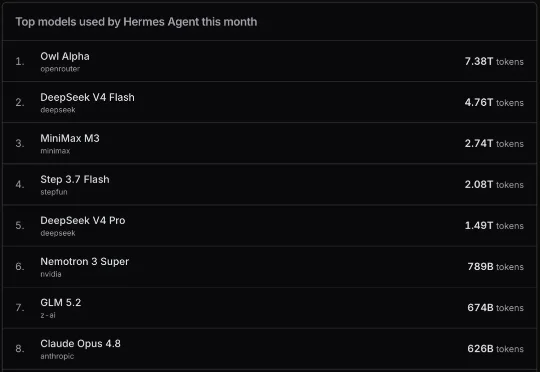
独家内幕:美团如何用5万张国产卡训出“龙猫”万亿级模型?最近几个月,一个名为“Owl Alpha”的神秘模型持续霸榜OpenRouter。它调用量长期位居全球前三,在Hermes、Claude Code和OpenClaw几大Agent模型中分别位列第一、第二和第三,不少开发者将其称为今年最令人意外的一匹“黑马”。
来自主题: AI资讯
7951 点击 2026-07-02 21:36
 搜索
搜索
最近几个月,一个名为“Owl Alpha”的神秘模型持续霸榜OpenRouter。它调用量长期位居全球前三,在Hermes、Claude Code和OpenClaw几大Agent模型中分别位列第一、第二和第三,不少开发者将其称为今年最令人意外的一匹“黑马”。

VAST 本月再次完成超 10 亿元人民币 A3 战略轮融资。一个月之前,这家公司刚刚披露完成约 2 亿美元融资,并正式披露世界模型项目 Project Eden。连续融资当然是一个重要信号。但这一轮更值得关注的,不只是金额,还有投资方的构成。
Base44 是一家 vibe-coding 平台,一年前被 Wix 以 8000 万美元收购。当时,这家公司成立还不到六个月,团队只有 8 个人。如今,Base44 开始推出自己的 AI 模型,帮助用户通过自然语言创建应用。
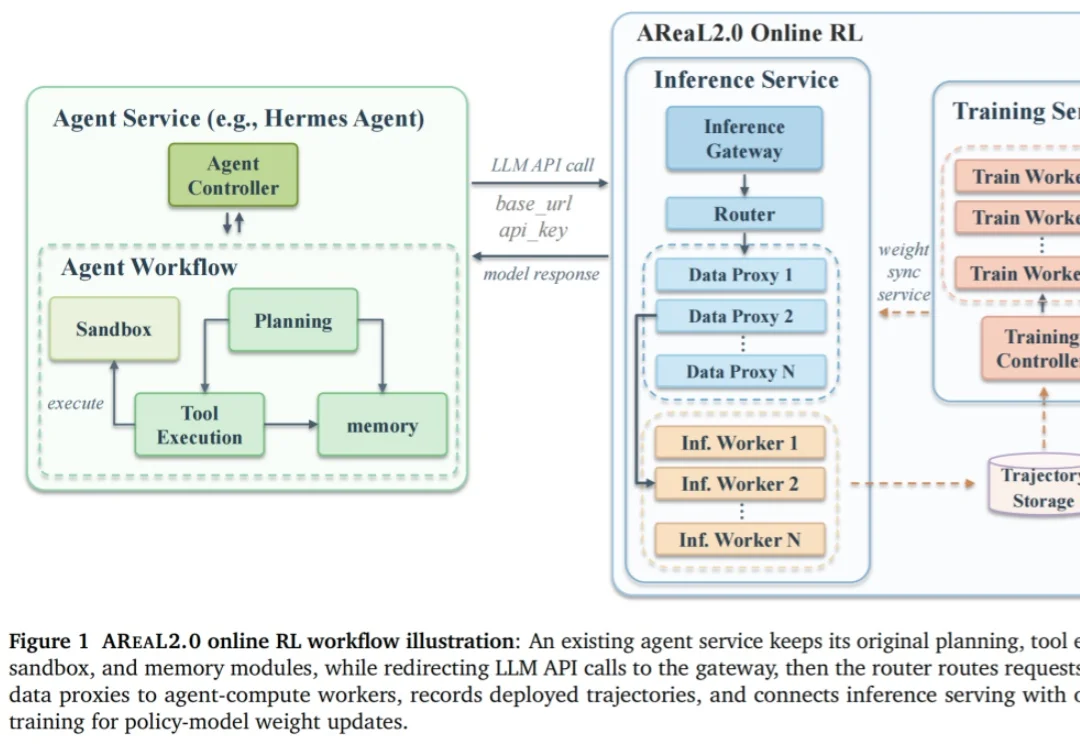
当 Agent 从演示视频中的炫技片段开始走进真实工作流与生产环境,下一阶段的「何去何从」成为业界关注的焦点。
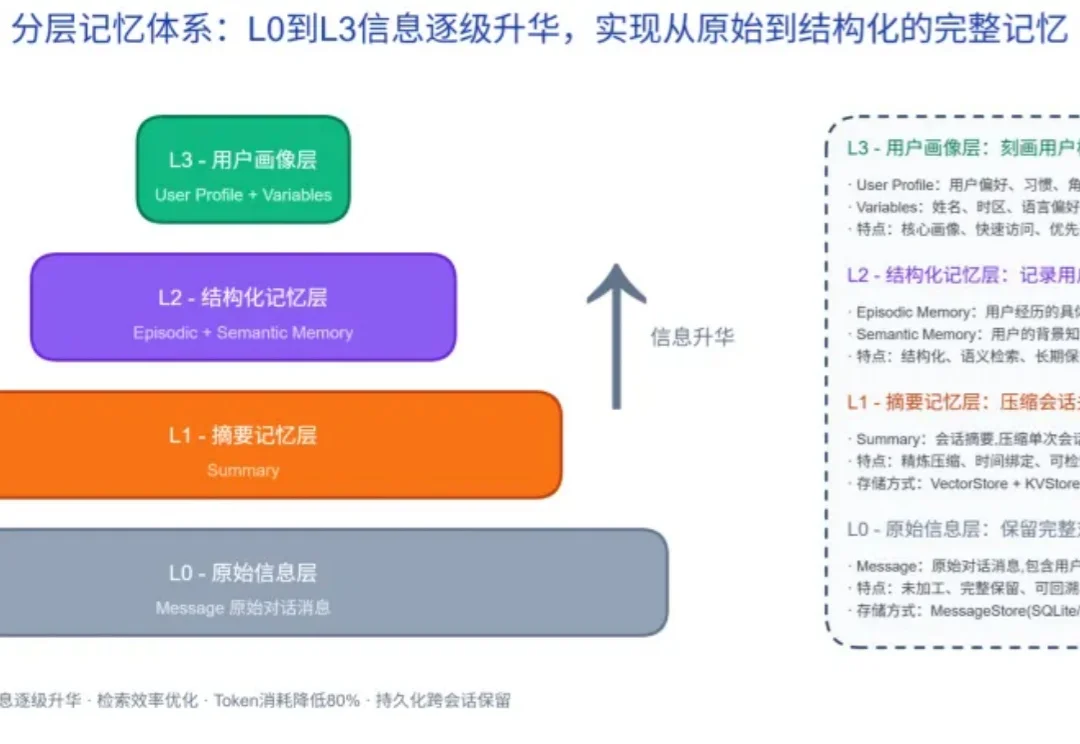
当大模型应用进入深水区,决定一个 Agent 体验上限的,早已不只是 "答得对不对", 而是 "能不能持续记住同一个人"。
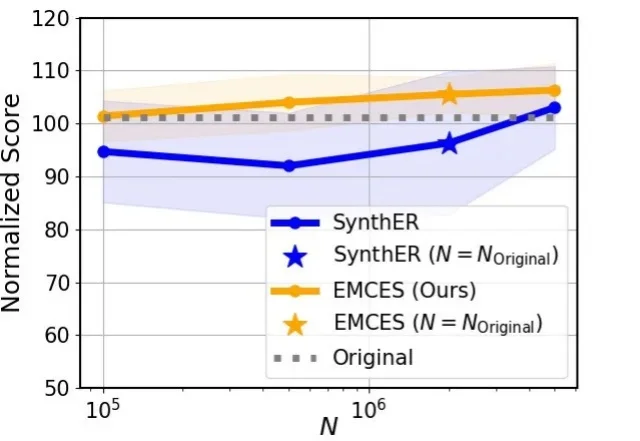
近年来,强化学习在游戏智能体、具身智能、大语言模型等领域取得了显著进展。然而,在真实世界中,强化学习仍面临一个核心难题:高质量样本的获取不仅成本高昂,还可能带来多种风险。因此,样本增强成为缓解强化学习中样本获取成本高、风险大等问题的重要途径之一。

Anthropic官宣Fable 5全球上线,安全测试中,亲手为8款模型,包括一款中国模型「盖章印证」。

具身智能数据的竞争,正在从“量大管饱”进入下一关。

模型卷不过,Meta 反手开门卖自家算力,直接抢 AWS 的饭碗——昔日金主 CoreWeave、Nebius 一夜被炸崩 17%。

据 Z Finance 获悉,由清华博士、华为「天才少年」张家声领衔的 AI 初创公司 Philo AI 已完成近千万级美金首轮融资,由祥峰投资(Vertex Ventures)独家投资。张家声此前主导的视频模型曾登上 Artificial Analysis 全球第 2,而这支核心成员全员清北博士的团队一向低调。本轮资金将重点用于世界生命模型的核心研发、自有系统构建与核心团队扩张。